在前面的很多文章中都提到过page结构体,但是并没有拿出来详细解释过,这里也详细的阐述一下吧。在 向pipe_buffer说yes! 文章中我们是使用off by null导致两个pipe_buffer->page指针指向了同一个page结构体,而page结构体在 Linux Kernel 中用于表示一个物理页框同样每个物理页框也会对应一个page结构体,正是因为前面的对应关系存在我们才能够让后面的pipe_buffer结构体去占领对应的物理页框。
structpage { unsignedlong flags; /* Atomic flags, some possibly * updated asynchronously */ /* * Five words (20/40 bytes) are available in this union. * WARNING: bit 0 of the first word is used for PageTail(). That * means the other users of this union MUST NOT use the bit to * avoid collision and false-positive PageTail(). */ union { struct {/* Page cache and anonymous pages */ /** * @lru: Pageout list, eg. active_list protected by * lruvec->lru_lock. Sometimes used as a generic list * by the page owner. */ union { structlist_headlru;
/* Or, for the Unevictable "LRU list" slot */ struct { /* Always even, to negate PageTail */ void *__filler; /* Count page's or folio's mlocks */ unsignedint mlock_count; };
/* Or, free page */ structlist_headbuddy_list; structlist_headpcp_list; }; /* See page-flags.h for PAGE_MAPPING_FLAGS */ structaddress_space *mapping; union { pgoff_t index; /* Our offset within mapping. */ unsignedlong share; /* share count for fsdax */ }; /** * @private: Mapping-private opaque data. * Usually used for buffer_heads if PagePrivate. * Used for swp_entry_t if PageSwapCache. * Indicates order in the buddy system if PageBuddy. */ unsignedlongprivate; }; struct {/* page_pool used by netstack */ /** * @pp_magic: magic value to avoid recycling non * page_pool allocated pages. */ unsignedlong pp_magic; structpage_pool *pp; unsignedlong _pp_mapping_pad; unsignedlong dma_addr; union { /** * dma_addr_upper: might require a 64-bit * value on 32-bit architectures. */ unsignedlong dma_addr_upper; /** * For frag page support, not supported in * 32-bit architectures with 64-bit DMA. */ atomic_long_t pp_frag_count; }; }; struct {/* Tail pages of compound page */ unsignedlong compound_head; /* Bit zero is set */ }; struct {/* ZONE_DEVICE pages */ /** @pgmap: Points to the hosting device page map. */ structdev_pagemap *pgmap; void *zone_device_data; /* * ZONE_DEVICE private pages are counted as being * mapped so the next 3 words hold the mapping, index, * and private fields from the source anonymous or * page cache page while the page is migrated to device * private memory. * ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also * use the mapping, index, and private fields when * pmem backed DAX files are mapped. */ };
/** @rcu_head: You can use this to free a page by RCU. */ structrcu_headrcu_head; };
union {/* This union is 4 bytes in size. */ /* * If the page can be mapped to userspace, encodes the number * of times this page is referenced by a page table. */ atomic_t _mapcount;
/* * If the page is neither PageSlab nor mappable to userspace, * the value stored here may help determine what this page * is used for. See page-flags.h for a list of page types * which are currently stored here. */ unsignedint page_type; };
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */ atomic_t _refcount;
/* * On machines where all RAM is mapped into kernel address space, * we can simply calculate the virtual address. On machines with * highmem some memory is mapped into kernel virtual memory * dynamically, so we need a place to store that address. * Note that this field could be 16 bits on x86 ... ;) * * Architectures with slow multiplication can define * WANT_PAGE_VIRTUAL in asm/page.h */ #if defined(WANT_PAGE_VIRTUAL) void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */ #endif/* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_KMSAN /* * KMSAN metadata for this page: * - shadow page: every bit indicates whether the corresponding * bit of the original page is initialized (0) or not (1); * - origin page: every 4 bytes contain an id of the stack trace * where the uninitialized value was created. */ structpage *kmsan_shadow; structpage *kmsan_origin; #endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS int _last_cpupid; #endif } _struct_page_alignment;
enumpageflags { PG_locked, /* Page is locked. Don't touch. */ PG_writeback, /* Page is under writeback */ PG_referenced, PG_uptodate, PG_dirty, PG_lru, PG_head, /* Must be in bit 6 */ PG_waiters, /* Page has waiters, check its waitqueue. Must be bit #7 and in the same byte as "PG_locked" */ PG_active, PG_workingset, PG_error, PG_slab, PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/ PG_arch_1, PG_reserved, PG_private, /* If pagecache, has fs-private data */ PG_private_2, /* If pagecache, has fs aux data */ PG_mappedtodisk, /* Has blocks allocated on-disk */ PG_reclaim, /* To be reclaimed asap */ PG_swapbacked, /* Page is backed by RAM/swap */ PG_unevictable, /* Page is "unevictable" */ #ifdef CONFIG_MMU PG_mlocked, /* Page is vma mlocked */ #endif #ifdef CONFIG_ARCH_USES_PG_UNCACHED PG_uncached, /* Page has been mapped as uncached */ #endif #ifdef CONFIG_MEMORY_FAILURE PG_hwpoison, /* hardware poisoned page. Don't touch */ #endif #if defined(CONFIG_PAGE_IDLE_FLAG) && defined(CONFIG_64BIT) PG_young, PG_idle, #endif #ifdef CONFIG_ARCH_USES_PG_ARCH_X PG_arch_2, PG_arch_3, #endif __NR_PAGEFLAGS,
PG_readahead = PG_reclaim,
/* * Depending on the way an anonymous folio can be mapped into a page * table (e.g., single PMD/PUD/CONT of the head page vs. PTE-mapped * THP), PG_anon_exclusive may be set only for the head page or for * tail pages of an anonymous folio. For now, we only expect it to be * set on tail pages for PTE-mapped THP. */ PG_anon_exclusive = PG_mappedtodisk,
/* Two page bits are conscripted by FS-Cache to maintain local caching * state. These bits are set on pages belonging to the netfs's inodes * when those inodes are being locally cached. */ PG_fscache = PG_private_2, /* page backed by cache */
/* XEN */ /* Pinned in Xen as a read-only pagetable page. */ PG_pinned = PG_owner_priv_1, /* Pinned as part of domain save (see xen_mm_pin_all()). */ PG_savepinned = PG_dirty, /* Has a grant mapping of another (foreign) domain's page. */ PG_foreign = PG_owner_priv_1, /* Remapped by swiotlb-xen. */ PG_xen_remapped = PG_owner_priv_1,
/* * Flags only valid for compound pages. Stored in first tail page's * flags word. Cannot use the first 8 flags or any flag marked as * PF_ANY. */
/* At least one page in this folio has the hwpoison flag set */ PG_has_hwpoisoned = PG_error, PG_hugetlb = PG_active, PG_large_rmappable = PG_workingset, /* anon or file-backed */ };
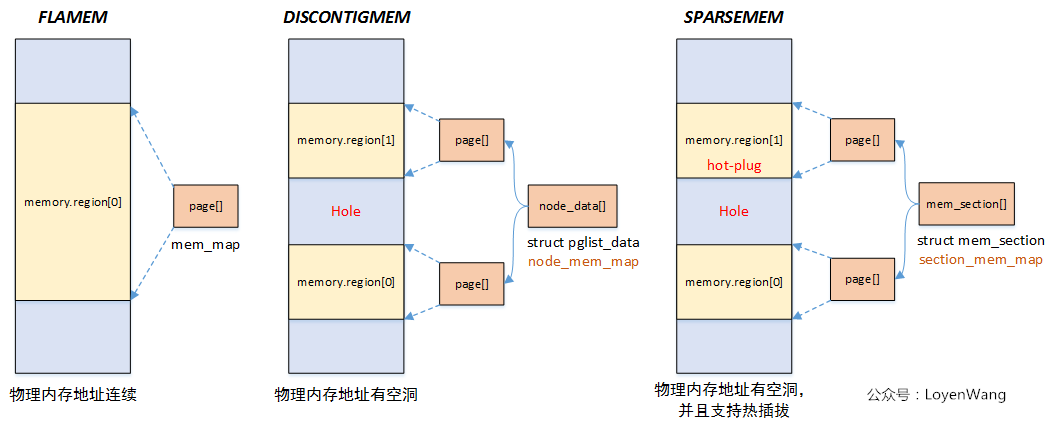
/* * page->flags layout: * * There are five possibilities for how page->flags get laid out. The first * pair is for the normal case without sparsemem. The second pair is for * sparsemem when there is plenty of space for node and section information. * The last is when there is insufficient space in page->flags and a separate * lookup is necessary. * * No sparsemem or sparsemem vmemmap: | NODE | ZONE | ... | FLAGS | * " plus space for last_cpupid: | NODE | ZONE | LAST_CPUPID ... | FLAGS | * classic sparse with space for node:| SECTION | NODE | ZONE | ... | FLAGS | * " plus space for last_cpupid: | SECTION | NODE | ZONE | LAST_CPUPID ... | FLAGS | * classic sparse no space for node: | SECTION | ZONE | ... | FLAGS | */
/* * For some devmap managed pages we need to catch refcount transition * from 2 to 1: */ if (put_devmap_managed_page(&folio->page)) return; folio_put(folio); }
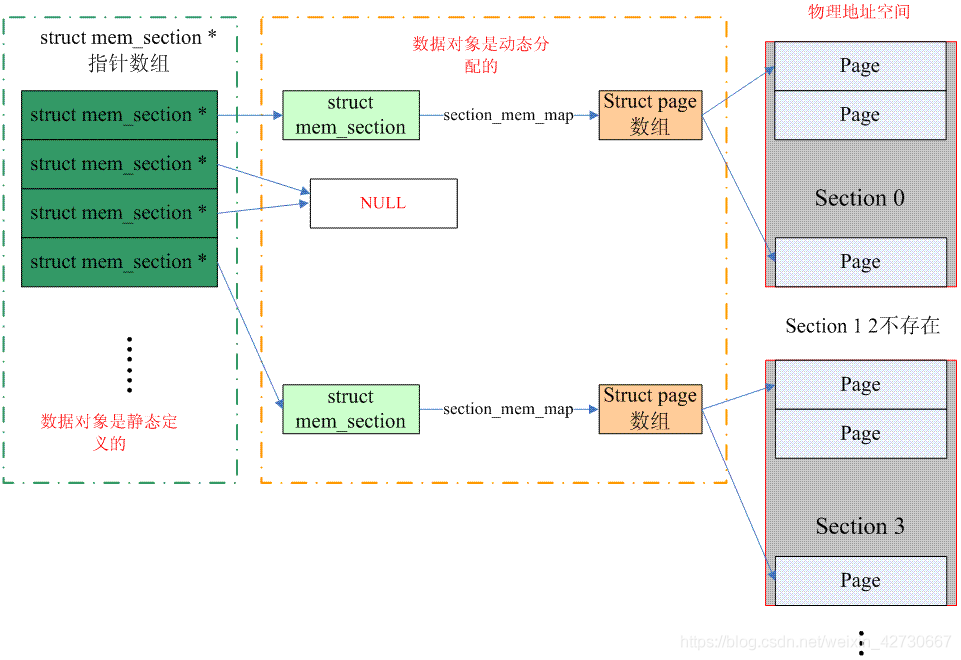
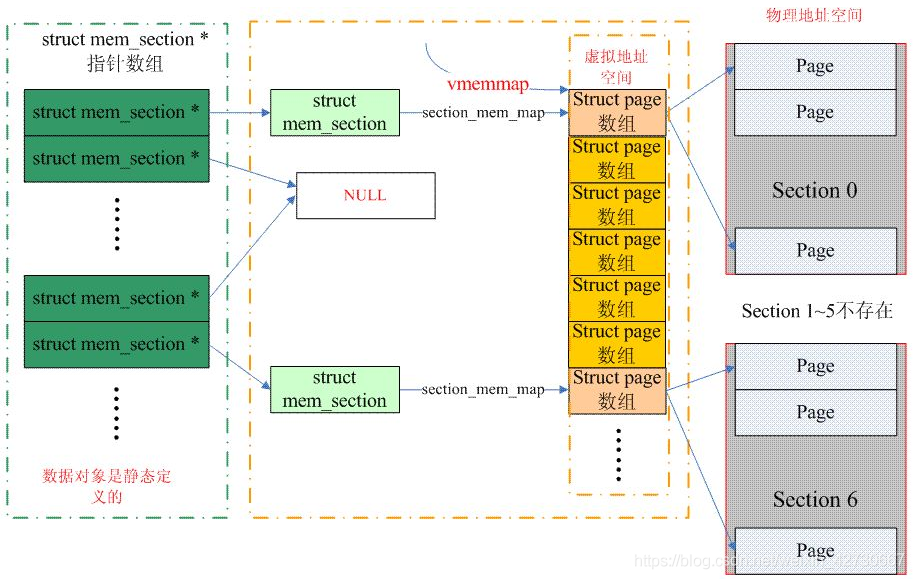
structmem_section { /* * This is, logically, a pointer to an array of struct * pages. However, it is stored with some other magic. * (see sparse.c::sparse_init_one_section()) * * Additionally during early boot we encode node id of * the location of the section here to guide allocation. * (see sparse.c::memory_present()) * * Making it a UL at least makes someone do a cast * before using it wrong. */ unsignedlong section_mem_map;
structmem_section_usage *usage; #ifdef CONFIG_PAGE_EXTENSION /* * If SPARSEMEM, pgdat doesn't have page_ext pointer. We use * section. (see page_ext.h about this.) */ structpage_ext *page_ext; unsignedlong pad; #endif /* * WARNING: mem_section must be a power-of-2 in size for the * calculation and use of SECTION_ROOT_MASK to make sense. */ };
/* zone watermarks, access with *_wmark_pages(zone) macros */ unsignedlong _watermark[NR_WMARK]; unsignedlong watermark_boost;
unsignedlong nr_reserved_highatomic;
/* * We don't know if the memory that we're going to allocate will be * freeable or/and it will be released eventually, so to avoid totally * wasting several GB of ram we must reserve some of the lower zone * memory (otherwise we risk to run OOM on the lower zones despite * there being tons of freeable ram on the higher zones). This array is * recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl * changes. */ long lowmem_reserve[MAX_NR_ZONES];
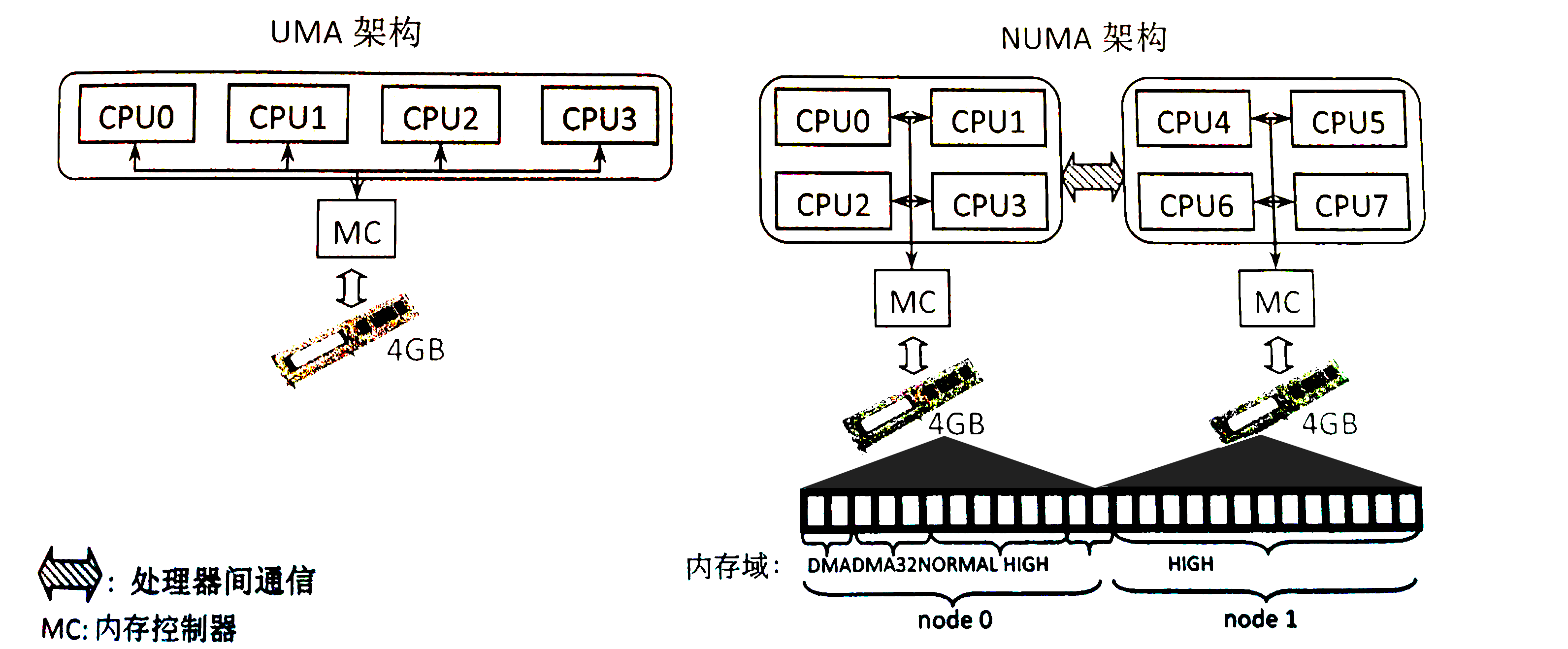
#ifdef CONFIG_NUMA int node; #endif structpglist_data *zone_pgdat; structper_cpu_pages __percpu *per_cpu_pageset; structper_cpu_zonestat __percpu *per_cpu_zonestats; /* * the high and batch values are copied to individual pagesets for * faster access */ int pageset_high; int pageset_batch;
#ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsignedlong *pageblock_flags; #endif/* CONFIG_SPARSEMEM */
/* * spanned_pages is the total pages spanned by the zone, including * holes, which is calculated as: * spanned_pages = zone_end_pfn - zone_start_pfn; * * present_pages is physical pages existing within the zone, which * is calculated as: * present_pages = spanned_pages - absent_pages(pages in holes); * * present_early_pages is present pages existing within the zone * located on memory available since early boot, excluding hotplugged * memory. * * managed_pages is present pages managed by the buddy system, which * is calculated as (reserved_pages includes pages allocated by the * bootmem allocator): * managed_pages = present_pages - reserved_pages; * * cma pages is present pages that are assigned for CMA use * (MIGRATE_CMA). * * So present_pages may be used by memory hotplug or memory power * management logic to figure out unmanaged pages by checking * (present_pages - managed_pages). And managed_pages should be used * by page allocator and vm scanner to calculate all kinds of watermarks * and thresholds. * * Locking rules: * * zone_start_pfn and spanned_pages are protected by span_seqlock. * It is a seqlock because it has to be read outside of zone->lock, * and it is done in the main allocator path. But, it is written * quite infrequently. * * The span_seq lock is declared along with zone->lock because it is * frequently read in proximity to zone->lock. It's good to * give them a chance of being in the same cacheline. * * Write access to present_pages at runtime should be protected by * mem_hotplug_begin/done(). Any reader who can't tolerant drift of * present_pages should use get_online_mems() to get a stable value. */ atomic_long_t managed_pages; unsignedlong spanned_pages; unsignedlong present_pages; #if defined(CONFIG_MEMORY_HOTPLUG) unsignedlong present_early_pages; #endif #ifdef CONFIG_CMA unsignedlong cma_pages; #endif
constchar *name;
#ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ unsignedlong nr_isolate_pageblock; #endif
#ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif
int initialized;
/* Write-intensive fields used from the page allocator */ CACHELINE_PADDING(_pad1_);
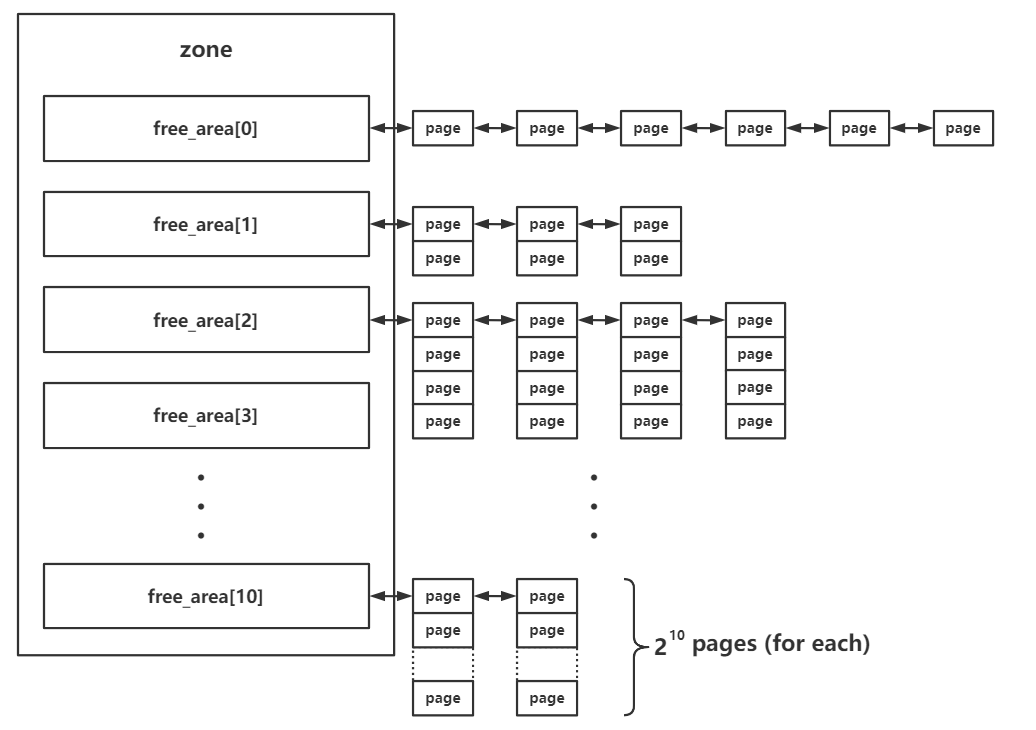
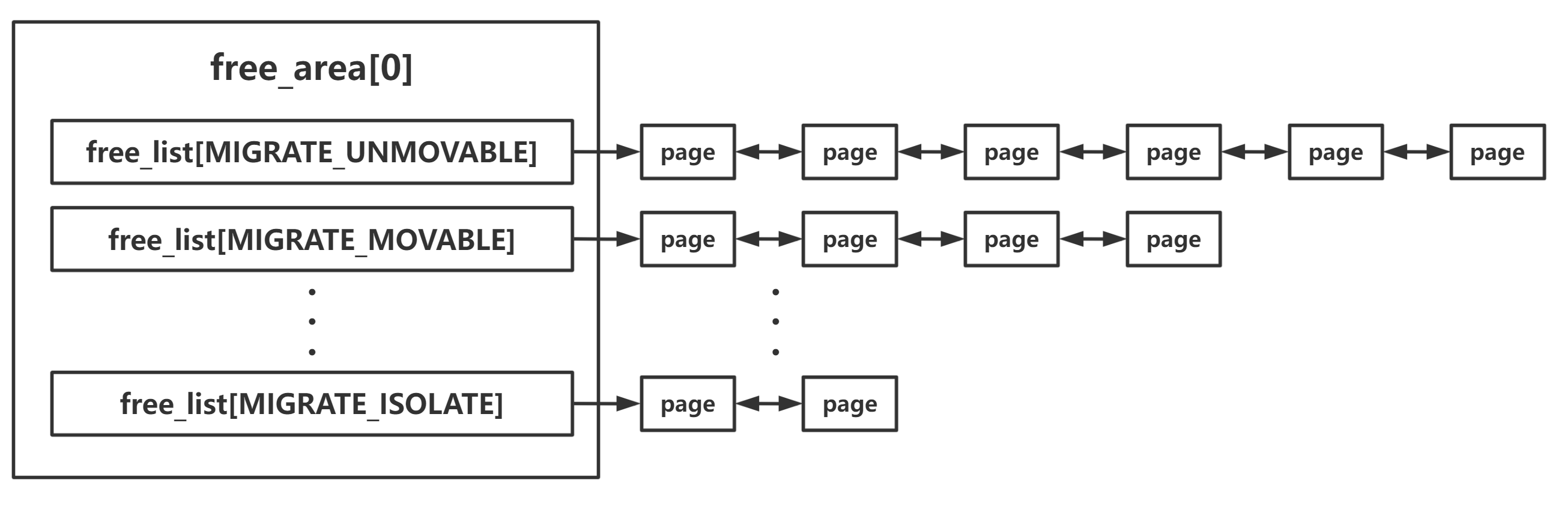
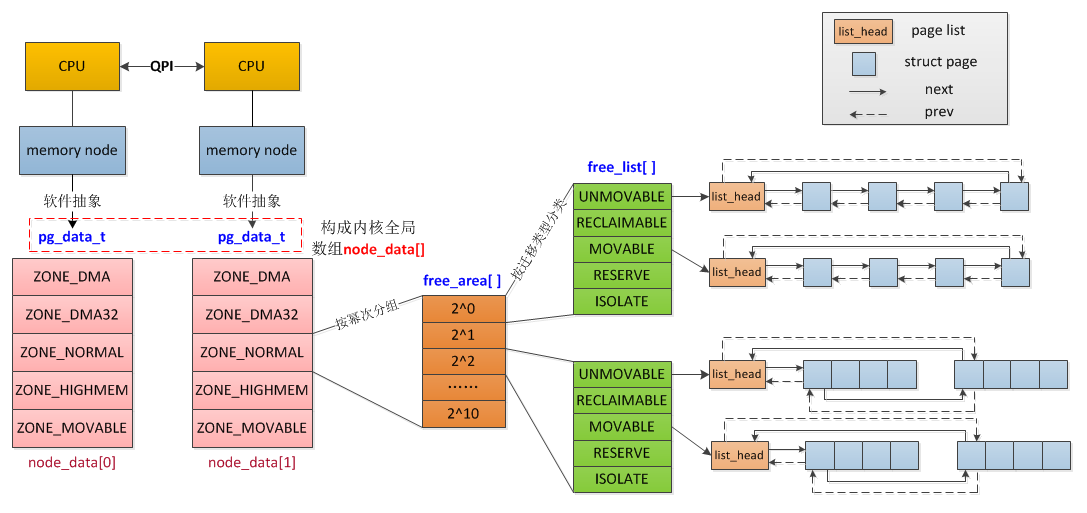
/* free areas of different sizes */ structfree_areafree_area[MAX_ORDER + 1];
#ifdef CONFIG_UNACCEPTED_MEMORY /* Pages to be accepted. All pages on the list are MAX_ORDER */ structlist_headunaccepted_pages; #endif
/* Write-intensive fields used by compaction and vmstats. */ CACHELINE_PADDING(_pad2_);
/* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsignedlong percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsignedlong compact_cached_free_pfn; /* pfn where compaction migration scanner should start */ unsignedlong compact_cached_migrate_pfn[ASYNC_AND_SYNC]; unsignedlong compact_init_migrate_pfn; unsignedlong compact_init_free_pfn; #endif
#ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. * compact_order_failed is the minimum compaction failed order. */ unsignedint compact_considered; unsignedint compact_defer_shift; int compact_order_failed; #endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif
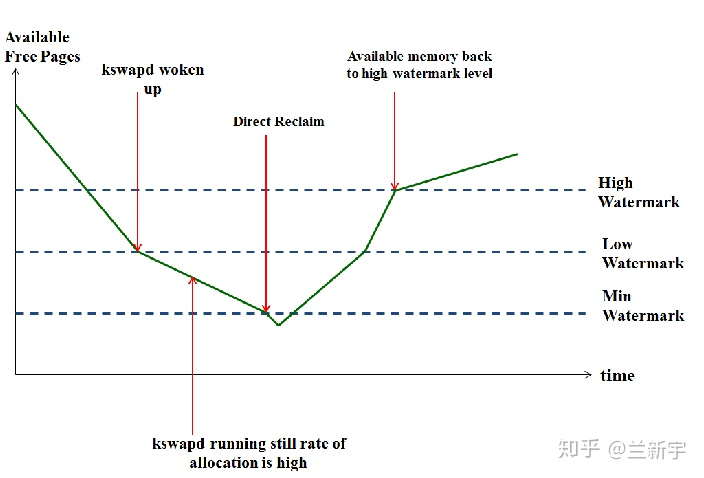
每一个 zone 都有着其对应的三档“水位线”: WMARK_MIN、WMARK_LOW、WMARK_HIGH,存放在 _watermark 数组中,在进行内存分配时,分配器(例如 buddy system)会根据当前 zone 中空余内存所处在的“水位线”来判断当前的内存状况。在进行内存分配的时候,如果分配器(比如buddy allocator)发现当前空余内存的值低于”low”但高于”min”,说明现在内存面临一定的压力,那么在此次内存分配完成后,kswapd将被唤醒,以执行内存回收操作。在这种情况下,内存分配虽然会触发内存回收,但不存在被内存回收所阻塞的问题,两者的执行关系是异步的(之前的kswapd实现是周期性触发)。”low”可以被认为是一个警戒水位线,而”high”则是一个安全的水位线。
lowmem_reserve:zone自身的保留内存
在进行内存分配时,若当前的 zone 没有足够的内存了,则会向下一个 zone 索要内存,那么这就存在一个问题:来自 higher zones 的内存分配请求可能耗尽 lower zones 的内存,但这样分配的内存未必是可释放的(freeable),亦或者/且最终不一定会被释放,这有可能导致 lower zones 的内存提前耗尽,而 higher zones 却仍保留有大量的内存
为了避免这样的一种情况的发生,lowmem_reserve 字段用以声明为该 zone 保留的内存,这一块内存别的 zone 是不能动的
node:NUMA中标识所属node
只有在CONFIG_NUMA即开启NUMA时该字段才会被启用,用来标识该zone所属的node。
zone_pgdat:zone 所属的 pglist_data 节点
该字段用以标识该 zone 所属的 pglist_data 节点
per_cpu_pageset:zone 为每个 CPU 划分一个独立的”页面仓库“
众所周知伴随着多 CPU 的引入,条件竞争就是一个不可忽视的问题,当多个 CPU 需要对一个 zone 进行操作时,频繁的加锁/解锁操作则毫无疑问会造成大量的开销,因此 zone 引入了 per_cpu_pageset 结构体成员,即为每一个 CPU 都准备一个单独的页面仓库,因此其实现方式是实现为一个 percpu 变量。在一开始时buddy system会将页面放置到各个 CPU 自己独立的页面仓库中,需要进行分配时 CPU 优先从自己的页面仓库中分配。
1 2 3 4 5 6 7 8 9 10 11 12 13
structper_cpu_pages { spinlock_t lock; /* Protects lists field */ int count; /* number of pages in the list */ int high; /* high watermark, emptying needed */ int batch; /* chunk size for buddy add/remove */ short free_factor; /* batch scaling factor during free */ #ifdef CONFIG_NUMA short expire; /* When 0, remote pagesets are drained */ #endif
/* Lists of pages, one per migrate type stored on the pcp-lists */ structlist_headlists[NR_PCP_LISTS]; } ____cacheline_aligned_in_smp;
该结构体会被存放在每个 CPU 自己独立的 .data..percpu 段中。
vm_stat:统计数据
该数组用来进行数据统计,按照枚举类型 zone_stat_item 分为多个数组,以统计不同类型的数据(比如说 NR_FREE_PAGES 表示 zone 中的空闲页面1数量):
enummigratetype { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
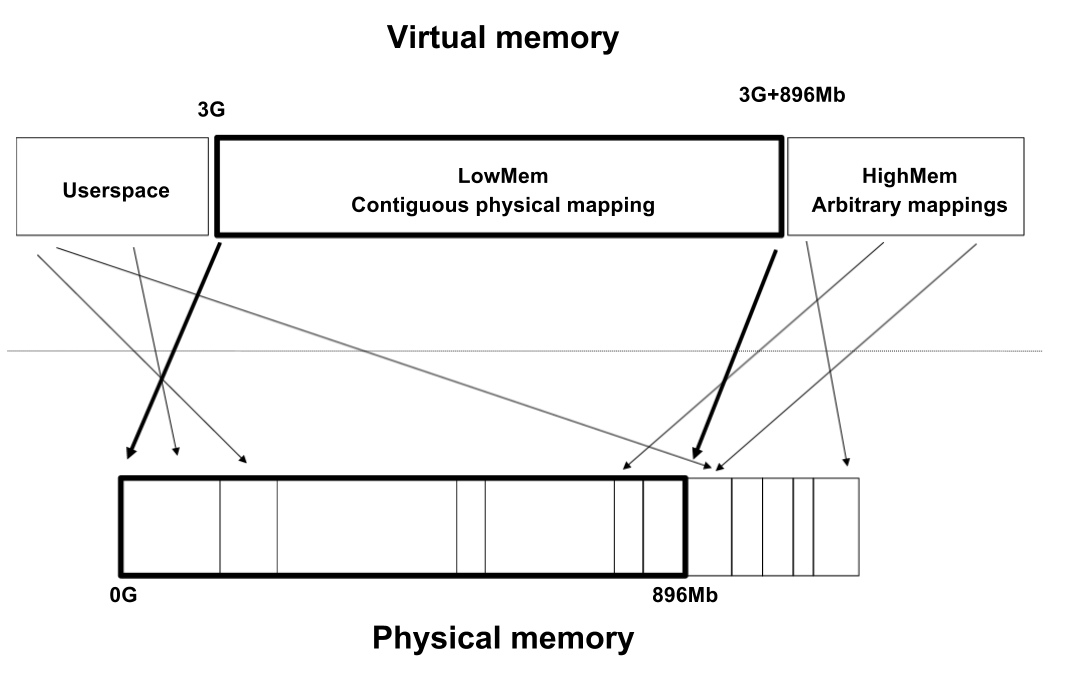
enumzone_type { /* * ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able * to DMA to all of the addressable memory (ZONE_NORMAL). * On architectures where this area covers the whole 32 bit address * space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller * DMA addressing constraints. This distinction is important as a 32bit * DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit * platforms may need both zones as they support peripherals with * different DMA addressing limitations. */ #ifdef CONFIG_ZONE_DMA ZONE_DMA, #endif #ifdef CONFIG_ZONE_DMA32 ZONE_DMA32, #endif /* * Normal addressable memory is in ZONE_NORMAL. DMA operations can be * performed on pages in ZONE_NORMAL if the DMA devices support * transfers to all addressable memory. */ ZONE_NORMAL, #ifdef CONFIG_HIGHMEM /* * A memory area that is only addressable by the kernel through * mapping portions into its own address space. This is for example * used by i386 to allow the kernel to address the memory beyond * 900MB. The kernel will set up special mappings (page * table entries on i386) for each page that the kernel needs to * access. */ ZONE_HIGHMEM, #endif /* * ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains * movable pages with few exceptional cases described below. Main use * cases for ZONE_MOVABLE are to make memory offlining/unplug more * likely to succeed, and to locally limit unmovable allocations - e.g., * to increase the number of THP/huge pages. Notable special cases are: * * 1. Pinned pages: (long-term) pinning of movable pages might * essentially turn such pages unmovable. Therefore, we do not allow * pinning long-term pages in ZONE_MOVABLE. When pages are pinned and * faulted, they come from the right zone right away. However, it is * still possible that address space already has pages in * ZONE_MOVABLE at the time when pages are pinned (i.e. user has * touches that memory before pinning). In such case we migrate them * to a different zone. When migration fails - pinning fails. * 2. memblock allocations: kernelcore/movablecore setups might create * situations where ZONE_MOVABLE contains unmovable allocations * after boot. Memory offlining and allocations fail early. * 3. Memory holes: kernelcore/movablecore setups might create very rare * situations where ZONE_MOVABLE contains memory holes after boot, * for example, if we have sections that are only partially * populated. Memory offlining and allocations fail early. * 4. PG_hwpoison pages: while poisoned pages can be skipped during * memory offlining, such pages cannot be allocated. * 5. Unmovable PG_offline pages: in paravirtualized environments, * hotplugged memory blocks might only partially be managed by the * buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The * parts not manged by the buddy are unmovable PG_offline pages. In * some cases (virtio-mem), such pages can be skipped during * memory offlining, however, cannot be moved/allocated. These * techniques might use alloc_contig_range() to hide previously * exposed pages from the buddy again (e.g., to implement some sort * of memory unplug in virtio-mem). * 6. ZERO_PAGE(0), kernelcore/movablecore setups might create * situations where ZERO_PAGE(0) which is allocated differently * on different platforms may end up in a movable zone. ZERO_PAGE(0) * cannot be migrated. * 7. Memory-hotplug: when using memmap_on_memory and onlining the * memory to the MOVABLE zone, the vmemmap pages are also placed in * such zone. Such pages cannot be really moved around as they are * self-stored in the range, but they are treated as movable when * the range they describe is about to be offlined. * * In general, no unmovable allocations that degrade memory offlining * should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range()) * have to expect that migrating pages in ZONE_MOVABLE can fail (even * if has_unmovable_pages() states that there are no unmovable pages, * there can be false negatives). */ ZONE_MOVABLE, #ifdef CONFIG_ZONE_DEVICE ZONE_DEVICE, #endif __MAX_NR_ZONES
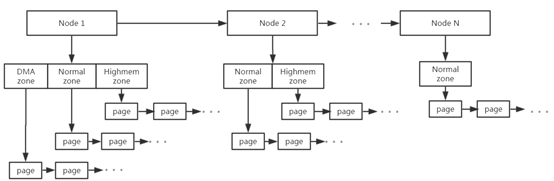
typedefstructpglist_data { /* * node_zones contains just the zones for THIS node. Not all of the * zones may be populated, but it is the full list. It is referenced by * this node's node_zonelists as well as other node's node_zonelists. */ structzonenode_zones[MAX_NR_ZONES];
/* * node_zonelists contains references to all zones in all nodes. * Generally the first zones will be references to this node's * node_zones. */ structzonelistnode_zonelists[MAX_ZONELISTS];
int nr_zones; /* number of populated zones in this node */ #ifdef CONFIG_FLATMEM /* means !SPARSEMEM */ structpage *node_mem_map; #ifdef CONFIG_PAGE_EXTENSION structpage_ext *node_page_ext; #endif #endif #if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT) /* * Must be held any time you expect node_start_pfn, * node_present_pages, node_spanned_pages or nr_zones to stay constant. * Also synchronizes pgdat->first_deferred_pfn during deferred page * init. * * pgdat_resize_lock() and pgdat_resize_unlock() are provided to * manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG * or CONFIG_DEFERRED_STRUCT_PAGE_INIT. * * Nests above zone->lock and zone->span_seqlock */ spinlock_t node_size_lock; #endif unsignedlong node_start_pfn; unsignedlong node_present_pages; /* total number of physical pages */ unsignedlong node_spanned_pages; /* total size of physical page range, including holes */ int node_id; wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait;
/* workqueues for throttling reclaim for different reasons. */ wait_queue_head_t reclaim_wait[NR_VMSCAN_THROTTLE];
atomic_t nr_writeback_throttled;/* nr of writeback-throttled tasks */ unsignedlong nr_reclaim_start; /* nr pages written while throttled * when throttling started. */ #ifdef CONFIG_MEMORY_HOTPLUG structmutexkswapd_lock; #endif structtask_struct *kswapd;/* Protected by kswapd_lock */ int kswapd_order; enumzone_typekswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION int kcompactd_max_order; enumzone_typekcompactd_highest_zoneidx; wait_queue_head_t kcompactd_wait; structtask_struct *kcompactd; bool proactive_compact_trigger; #endif /* * This is a per-node reserve of pages that are not available * to userspace allocations. */ unsignedlong totalreserve_pages;
#ifdef CONFIG_NUMA /* * node reclaim becomes active if more unmapped pages exist. */ unsignedlong min_unmapped_pages; unsignedlong min_slab_pages; #endif/* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */ CACHELINE_PADDING(_pad1_);
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * If memory initialisation on large machines is deferred then this * is the first PFN that needs to be initialised. */ unsignedlong first_deferred_pfn; #endif/* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_NUMA_BALANCING /* start time in ms of current promote rate limit period */ unsignedint nbp_rl_start; /* number of promote candidate pages at start time of current rate limit period */ unsignedlong nbp_rl_nr_cand; /* promote threshold in ms */ unsignedint nbp_threshold; /* start time in ms of current promote threshold adjustment period */ unsignedint nbp_th_start; /* * number of promote candidate pages at start time of current promote * threshold adjustment period */ unsignedlong nbp_th_nr_cand; #endif /* Fields commonly accessed by the page reclaim scanner */
/* * NOTE: THIS IS UNUSED IF MEMCG IS ENABLED. * * Use mem_cgroup_lruvec() to look up lruvecs. */ structlruvec __lruvec;
unsignedlong flags;
#ifdef CONFIG_LRU_GEN /* kswap mm walk data */ structlru_gen_mm_walkmm_walk; /* lru_gen_folio list */ structlru_gen_memcgmemcg_lru; #endif
enumnode_states { N_POSSIBLE, /* The node could become online at some point */ N_ONLINE, /* The node is online */ N_NORMAL_MEMORY, /* The node has regular memory */ #ifdef CONFIG_HIGHMEM N_HIGH_MEMORY, /* The node has regular or high memory */ #else N_HIGH_MEMORY = N_NORMAL_MEMORY, #endif N_MEMORY, /* The node has memory(regular, high, movable) */ N_CPU, /* The node has one or more cpus */ N_GENERIC_INITIATOR, /* The node has one or more Generic Initiators */ NR_NODE_STATES };
structalloc_context { structzonelist *zonelist; nodemask_t *nodemask; structzoneref *preferred_zoneref; int migratetype;
/* * highest_zoneidx represents highest usable zone index of * the allocation request. Due to the nature of the zone, * memory on lower zone than the highest_zoneidx will be * protected by lowmem_reserve[highest_zoneidx]. * * highest_zoneidx is also used by reclaim/compaction to limit * the target zone since higher zone than this index cannot be * usable for this allocation request. */ enumzone_typehighest_zoneidx; bool spread_dirty_pages; };
structpage *__alloc_pages(gfp_tgfp, unsignedintorder, intpreferred_nid, nodemask_t *nodemask) { structpage *page; unsignedint alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */ structalloc_contextac = { };
/* * There are several places where we assume that the order value is sane * so bail out early if the request is out of bound. */ if (WARN_ON_ONCE_GFP(order > MAX_ORDER, gfp)) returnNULL;
gfp &= gfp_allowed_mask; /* * Apply scoped allocation constraints. This is mainly about GFP_NOFS * resp. GFP_NOIO which has to be inherited for all allocation requests * from a particular context which has been marked by * memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures * movable zones are not used during allocation. */ gfp = current_gfp_context(gfp); alloc_gfp = gfp; if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac, &alloc_gfp, &alloc_flags)) returnNULL;
/* * Forbid the first pass from falling back to types that fragment * memory until all local zones are considered. */ alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
/* First allocation attempt */ page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac); if (likely(page)) goto out;
alloc_gfp = gfp; ac.spread_dirty_pages = false;
/* * Restore the original nodemask if it was potentially replaced with * &cpuset_current_mems_allowed to optimize the fast-path attempt. */ ac.nodemask = nodemask;
if (cpusets_enabled()) { *alloc_gfp |= __GFP_HARDWALL; /* * When we are in the interrupt context, it is irrelevant * to the current task context. It means that any node ok. */ if (in_task() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; }
might_alloc(gfp_mask);
if (should_fail_alloc_page(gfp_mask, order)) returnfalse;
/* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/* * The preferred zone is used for statistics but crucially it is * also used as the starting point for the zonelist iterator. It * may get reset for allocations that ignore memory policies. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask);
retry: /* * Scan zonelist, looking for a zone with enough free. * See also cpuset_node_allowed() comment in kernel/cgroup/cpuset.c. */ no_fallback = alloc_flags & ALLOC_NOFRAGMENT; z = ac->preferred_zoneref; for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx, ac->nodemask) { structpage *page; unsignedlong mark;
if (cpusets_enabled() && (alloc_flags & ALLOC_CPUSET) && !__cpuset_zone_allowed(zone, gfp_mask)) continue; /* * When allocating a page cache page for writing, we * want to get it from a node that is within its dirty * limit, such that no single node holds more than its * proportional share of globally allowed dirty pages. * The dirty limits take into account the node's * lowmem reserves and high watermark so that kswapd * should be able to balance it without having to * write pages from its LRU list. * * XXX: For now, allow allocations to potentially * exceed the per-node dirty limit in the slowpath * (spread_dirty_pages unset) before going into reclaim, * which is important when on a NUMA setup the allowed * nodes are together not big enough to reach the * global limit. The proper fix for these situations * will require awareness of nodes in the * dirty-throttling and the flusher threads. */ if (ac->spread_dirty_pages) { if (last_pgdat != zone->zone_pgdat) { last_pgdat = zone->zone_pgdat; last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat); }
if (!last_pgdat_dirty_ok) continue; }
if (no_fallback && nr_online_nodes > 1 && zone != ac->preferred_zoneref->zone) { int local_nid;
/* * If moving to a remote node, retry but allow * fragmenting fallbacks. Locality is more important * than fragmentation avoidance. */ local_nid = zone_to_nid(ac->preferred_zoneref->zone); if (zone_to_nid(zone) != local_nid) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } }
/* * Detect whether the number of free pages is below high * watermark. If so, we will decrease pcp->high and free * PCP pages in free path to reduce the possibility of * premature page reclaiming. Detection is done here to * avoid to do that in hotter free path. */ if (test_bit(ZONE_BELOW_HIGH, &zone->flags)) goto check_alloc_wmark;
mark = high_wmark_pages(zone); if (zone_watermark_fast(zone, order, mark, ac->highest_zoneidx, alloc_flags, gfp_mask)) goto try_this_zone; else set_bit(ZONE_BELOW_HIGH, &zone->flags);
check_alloc_wmark: mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK); if (!zone_watermark_fast(zone, order, mark, ac->highest_zoneidx, alloc_flags, gfp_mask)) { int ret;
if (has_unaccepted_memory()) { if (try_to_accept_memory(zone, order)) goto try_this_zone; }
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* * Watermark failed for this zone, but see if we can * grow this zone if it contains deferred pages. */ if (deferred_pages_enabled()) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif /* Checked here to keep the fast path fast */ BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone;
if (!node_reclaim_enabled() || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: /* did not scan */ continue; case NODE_RECLAIM_FULL: /* scanned but unreclaimable */ continue; default: /* did we reclaim enough */ if (zone_watermark_ok(zone, order, mark, ac->highest_zoneidx, alloc_flags)) goto try_this_zone;
/* * If this is a high-order atomic allocation then check * if the pageblock should be reserved for the future */ if (unlikely(alloc_flags & ALLOC_HIGHATOMIC)) reserve_highatomic_pageblock(page, zone);
return page; } else { if (has_unaccepted_memory()) { if (try_to_accept_memory(zone, order)) goto try_this_zone; }
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT /* Try again if zone has deferred pages */ if (deferred_pages_enabled()) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif } }
/* * It's possible on a UMA machine to get through all zones that are * fragmented. If avoiding fragmentation, reset and try again. */ if (no_fallback) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; }
staticinline struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsignedint order, gfp_t gfp_flags, unsignedint alloc_flags, int migratetype) { structpage *page;
/* * We most definitely don't want callers attempting to * allocate greater than order-1 page units with __GFP_NOFAIL. */ WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
if (likely(pcp_allowed_order(order))) { page = rmqueue_pcplist(preferred_zone, zone, order, migratetype, alloc_flags); if (likely(page)) goto out; }
static struct page *rmqueue_pcplist(struct zone *preferred_zone, struct zone *zone, unsignedint order, int migratetype, unsignedint alloc_flags) { structper_cpu_pages *pcp; structlist_head *list; structpage *page; unsignedlong __maybe_unused UP_flags;
/* spin_trylock may fail due to a parallel drain or IRQ reentrancy. */ pcp_trylock_prepare(UP_flags); pcp = pcp_spin_trylock(zone->per_cpu_pageset); if (!pcp) { pcp_trylock_finish(UP_flags); returnNULL; }
/* * On allocation, reduce the number of pages that are batch freed. * See nr_pcp_free() where free_factor is increased for subsequent * frees. */ pcp->free_count >>= 1; list = &pcp->lists[order_to_pindex(migratetype, order)]; page = __rmqueue_pcplist(zone, order, migratetype, alloc_flags, pcp, list); pcp_spin_unlock(pcp); pcp_trylock_finish(UP_flags); if (page) { __count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order); zone_statistics(preferred_zone, zone, 1); } return page; }
staticintrmqueue_bulk(struct zone *zone, unsignedint order, unsignedlong count, struct list_head *list, int migratetype, unsignedint alloc_flags) { unsignedlong flags; int i;
spin_lock_irqsave(&zone->lock, flags); for (i = 0; i < count; ++i) { structpage *page = __rmqueue(zone, order, migratetype, alloc_flags); if (unlikely(page == NULL)) break;
/* * Split buddy pages returned by expand() are received here in * physical page order. The page is added to the tail of * caller's list. From the callers perspective, the linked list * is ordered by page number under some conditions. This is * useful for IO devices that can forward direction from the * head, thus also in the physical page order. This is useful * for IO devices that can merge IO requests if the physical * pages are ordered properly. */ list_add_tail(&page->pcp_list, list); if (is_migrate_cma(get_pcppage_migratetype(page))) __mod_zone_page_state(zone, NR_FREE_CMA_PAGES, -(1 << order)); }
static __always_inline struct page *rmqueue_buddy(struct zone *preferred_zone, struct zone *zone, unsignedint order, unsignedint alloc_flags, int migratetype) { structpage *page; unsignedlong flags;
do { page = NULL; spin_lock_irqsave(&zone->lock, flags); if (alloc_flags & ALLOC_HIGHATOMIC) page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC); if (!page) { page = __rmqueue(zone, order, migratetype, alloc_flags);
/* * If the allocation fails, allow OOM handling access * to HIGHATOMIC reserves as failing now is worse than * failing a high-order atomic allocation in the * future. */ if (!page && (alloc_flags & ALLOC_OOM)) page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (!page) { spin_unlock_irqrestore(&zone->lock, flags); returnNULL; } } __mod_zone_freepage_state(zone, -(1 << order), get_pcppage_migratetype(page)); spin_unlock_irqrestore(&zone->lock, flags); } while (check_new_pages(page, order));
if (IS_ENABLED(CONFIG_CMA)) { /* * Balance movable allocations between regular and CMA areas by * allocating from CMA when over half of the zone's free memory * is in the CMA area. */ if (alloc_flags & ALLOC_CMA && zone_page_state(zone, NR_FREE_CMA_PAGES) > zone_page_state(zone, NR_FREE_PAGES) / 2) { page = __rmqueue_cma_fallback(zone, order); if (page) return page; } } retry: page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (alloc_flags & ALLOC_CMA) page = __rmqueue_cma_fallback(zone, order);
/* * Mark as guard pages (or page), that will allow to * merge back to allocator when buddy will be freed. * Corresponding page table entries will not be touched, * pages will stay not present in virtual address space */ if (set_page_guard(zone, &page[size], high, migratetype)) continue;
/* * The fast path uses conservative alloc_flags to succeed only until * kswapd needs to be woken up, and to avoid the cost of setting up * alloc_flags precisely. So we do that now. */ alloc_flags = gfp_to_alloc_flags(gfp_mask, order);
/* * We need to recalculate the starting point for the zonelist iterator * because we might have used different nodemask in the fast path, or * there was a cpuset modification and we are retrying - otherwise we * could end up iterating over non-eligible zones endlessly. */ ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); if (!ac->preferred_zoneref->zone) goto nopage;
/* * Check for insane configurations where the cpuset doesn't contain * any suitable zone to satisfy the request - e.g. non-movable * GFP_HIGHUSER allocations from MOVABLE nodes only. */ if (cpusets_insane_config() && (gfp_mask & __GFP_HARDWALL)) { structzoneref *z = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, &cpuset_current_mems_allowed); if (!z->zone) goto nopage; }
if (alloc_flags & ALLOC_KSWAPD) wake_all_kswapds(order, gfp_mask, ac);
/* * The adjusted alloc_flags might result in immediate success, so try * that first */ page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg;
/* * For costly allocations, try direct compaction first, as it's likely * that we have enough base pages and don't need to reclaim. For non- * movable high-order allocations, do that as well, as compaction will * try prevent permanent fragmentation by migrating from blocks of the * same migratetype. * Don't try this for allocations that are allowed to ignore * watermarks, as the ALLOC_NO_WATERMARKS attempt didn't yet happen. */ if (can_direct_reclaim && (costly_order || (order > 0 && ac->migratetype != MIGRATE_MOVABLE)) && !gfp_pfmemalloc_allowed(gfp_mask)) { page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac, INIT_COMPACT_PRIORITY, &compact_result); if (page) goto got_pg;
/* * Checks for costly allocations with __GFP_NORETRY, which * includes some THP page fault allocations */ if (costly_order && (gfp_mask & __GFP_NORETRY)) { /* * If allocating entire pageblock(s) and compaction * failed because all zones are below low watermarks * or is prohibited because it recently failed at this * order, fail immediately unless the allocator has * requested compaction and reclaim retry. * * Reclaim is * - potentially very expensive because zones are far * below their low watermarks or this is part of very * bursty high order allocations, * - not guaranteed to help because isolate_freepages() * may not iterate over freed pages as part of its * linear scan, and * - unlikely to make entire pageblocks free on its * own. */ if (compact_result == COMPACT_SKIPPED || compact_result == COMPACT_DEFERRED) goto nopage;
/* * Looks like reclaim/compaction is worth trying, but * sync compaction could be very expensive, so keep * using async compaction. */ compact_priority = INIT_COMPACT_PRIORITY; } }
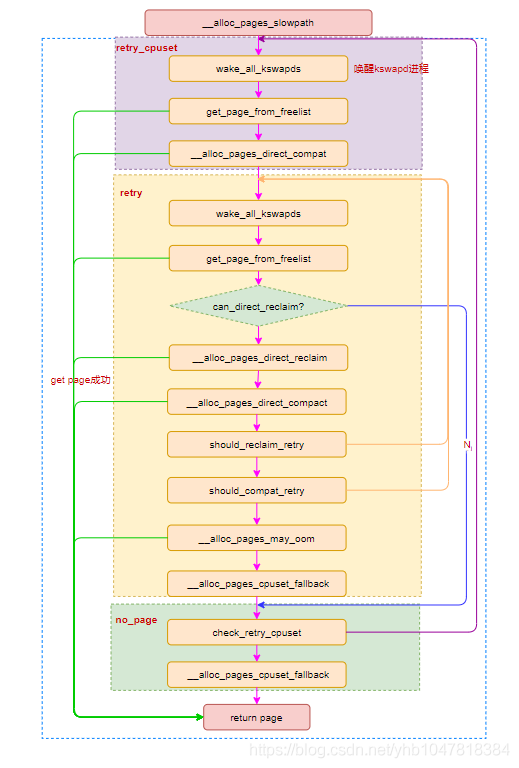
retry: /* Ensure kswapd doesn't accidentally go to sleep as long as we loop */ if (alloc_flags & ALLOC_KSWAPD) wake_all_kswapds(order, gfp_mask, ac);
/* * Reset the nodemask and zonelist iterators if memory policies can be * ignored. These allocations are high priority and system rather than * user oriented. */ if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) { ac->nodemask = NULL; ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); }
/* Attempt with potentially adjusted zonelist and alloc_flags */ page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac); if (page) goto got_pg;
/* Caller is not willing to reclaim, we can't balance anything */ if (!can_direct_reclaim) goto nopage;
/* Avoid recursion of direct reclaim */ if (current->flags & PF_MEMALLOC) goto nopage;
/* Try direct reclaim and then allocating */ page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac, &did_some_progress); if (page) goto got_pg;
/* Try direct compaction and then allocating */ page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac, compact_priority, &compact_result); if (page) goto got_pg;
/* Do not loop if specifically requested */ if (gfp_mask & __GFP_NORETRY) goto nopage;
/* * Do not retry costly high order allocations unless they are * __GFP_RETRY_MAYFAIL */ if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL)) goto nopage;
/* * It doesn't make any sense to retry for the compaction if the order-0 * reclaim is not able to make any progress because the current * implementation of the compaction depends on the sufficient amount * of free memory (see __compaction_suitable) */ if (did_some_progress > 0 && should_compact_retry(ac, order, alloc_flags, compact_result, &compact_priority, &compaction_retries)) goto retry;
/* * Deal with possible cpuset update races or zonelist updates to avoid * a unnecessary OOM kill. */ if (check_retry_cpuset(cpuset_mems_cookie, ac) || check_retry_zonelist(zonelist_iter_cookie)) goto restart;
/* Reclaim has failed us, start killing things */ page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress); if (page) goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */ if (tsk_is_oom_victim(current) && (alloc_flags & ALLOC_OOM || (gfp_mask & __GFP_NOMEMALLOC))) goto nopage;
/* Retry as long as the OOM killer is making progress */ if (did_some_progress) { no_progress_loops = 0; goto retry; }
nopage: /* * Deal with possible cpuset update races or zonelist updates to avoid * a unnecessary OOM kill. */ if (check_retry_cpuset(cpuset_mems_cookie, ac) || check_retry_zonelist(zonelist_iter_cookie)) goto restart;
/* * Make sure that __GFP_NOFAIL request doesn't leak out and make sure * we always retry */ if (gfp_mask & __GFP_NOFAIL) { /* * All existing users of the __GFP_NOFAIL are blockable, so warn * of any new users that actually require GFP_NOWAIT */ if (WARN_ON_ONCE_GFP(!can_direct_reclaim, gfp_mask)) goto fail;
/* * PF_MEMALLOC request from this context is rather bizarre * because we cannot reclaim anything and only can loop waiting * for somebody to do a work for us */ WARN_ON_ONCE_GFP(current->flags & PF_MEMALLOC, gfp_mask);
/* * non failing costly orders are a hard requirement which we * are not prepared for much so let's warn about these users * so that we can identify them and convert them to something * else. */ WARN_ON_ONCE_GFP(costly_order, gfp_mask);
/* * Help non-failing allocations by giving some access to memory * reserves normally used for high priority non-blocking * allocations but do not use ALLOC_NO_WATERMARKS because this * could deplete whole memory reserves which would just make * the situation worse. */ page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_MIN_RESERVE, ac); if (page) goto got_pg;
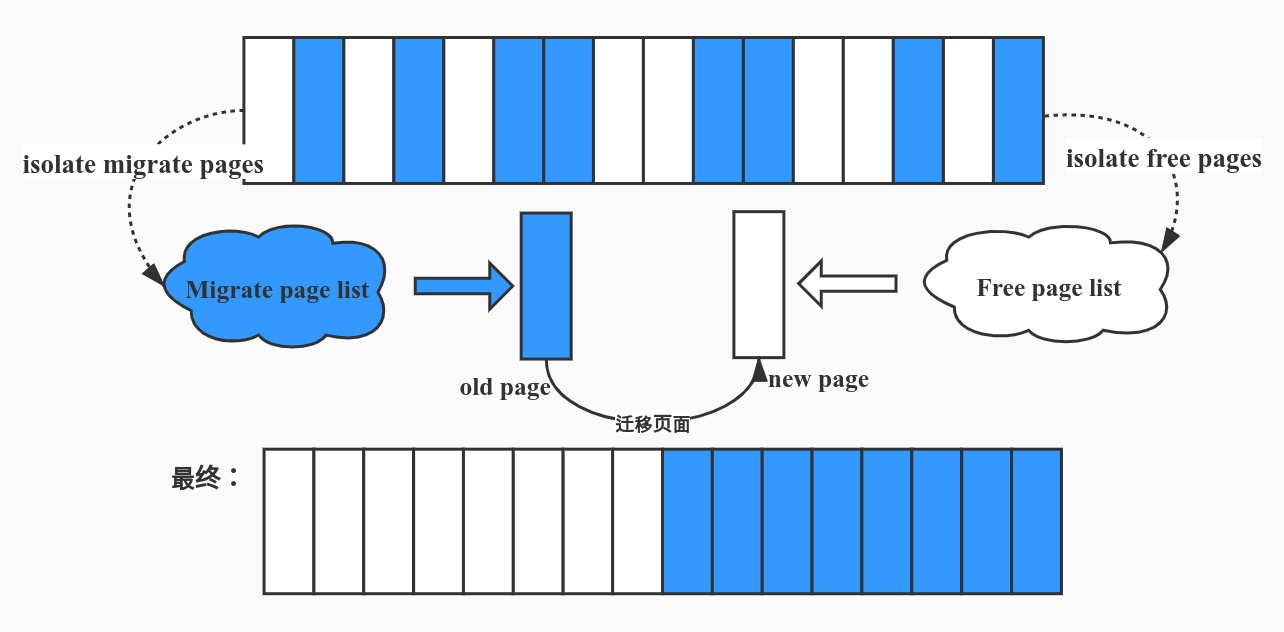
/* * Freeing function for a buddy system allocator. * * The concept of a buddy system is to maintain direct-mapped table * (containing bit values) for memory blocks of various "orders". * The bottom level table contains the map for the smallest allocatable * units of memory (here, pages), and each level above it describes * pairs of units from the levels below, hence, "buddies". * At a high level, all that happens here is marking the table entry * at the bottom level available, and propagating the changes upward * as necessary, plus some accounting needed to play nicely with other * parts of the VM system. * At each level, we keep a list of pages, which are heads of continuous * free pages of length of (1 << order) and marked with PageBuddy. * Page's order is recorded in page_private(page) field. * So when we are allocating or freeing one, we can derive the state of the * other. That is, if we allocate a small block, and both were * free, the remainder of the region must be split into blocks. * If a block is freed, and its buddy is also free, then this * triggers coalescing into a block of larger size. * * -- nyc */
while (order < MAX_ORDER) { if (compaction_capture(capc, page, order, migratetype)) { __mod_zone_freepage_state(zone, -(1 << order), migratetype); return; }
buddy = find_buddy_page_pfn(page, pfn, order, &buddy_pfn); if (!buddy) goto done_merging;
if (unlikely(order >= pageblock_order)) { /* * We want to prevent merge between freepages on pageblock * without fallbacks and normal pageblock. Without this, * pageblock isolation could cause incorrect freepage or CMA * accounting or HIGHATOMIC accounting. */ int buddy_mt = get_pfnblock_migratetype(buddy, buddy_pfn);
/* * Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page, * merge with it and move up one order. */ if (page_is_guard(buddy)) clear_page_guard(zone, buddy, order, migratetype); else del_page_from_free_list(buddy, zone, order); combined_pfn = buddy_pfn & pfn; page = page + (combined_pfn - pfn); pfn = combined_pfn; order++; }
/* Notify page reporting subsystem of freed page */ if (!(fpi_flags & FPI_SKIP_REPORT_NOTIFY)) page_reporting_notify_free(order); }
该函数,主要作用是将特定页面释放到特定 zone 上,需要注意的是这里的 one page 不是一张页框而是一块连续内存(可能有多张页)。这是一个释放页面的基本函数,故我们需要提供待释放页面的页结构体(struct page)、页框号、页面块的阶(order)、目标 zone、迁移类型等信息——这些信息通常由上层封装函数提供,这个函数所做的只是简单地将页挂回对应链表并检查合并的操作。该函数是 buddy system 中用以进行页面释放的核心函数,所有的页面释放 API 都是基于该函数的封装。
if (!free_pages_prepare(page, order, fpi_flags)) return;
/* * Calling get_pfnblock_migratetype() without spin_lock_irqsave() here * is used to avoid calling get_pfnblock_migratetype() under the lock. * This will reduce the lock holding time. */ migratetype = get_pfnblock_migratetype(page, pfn);