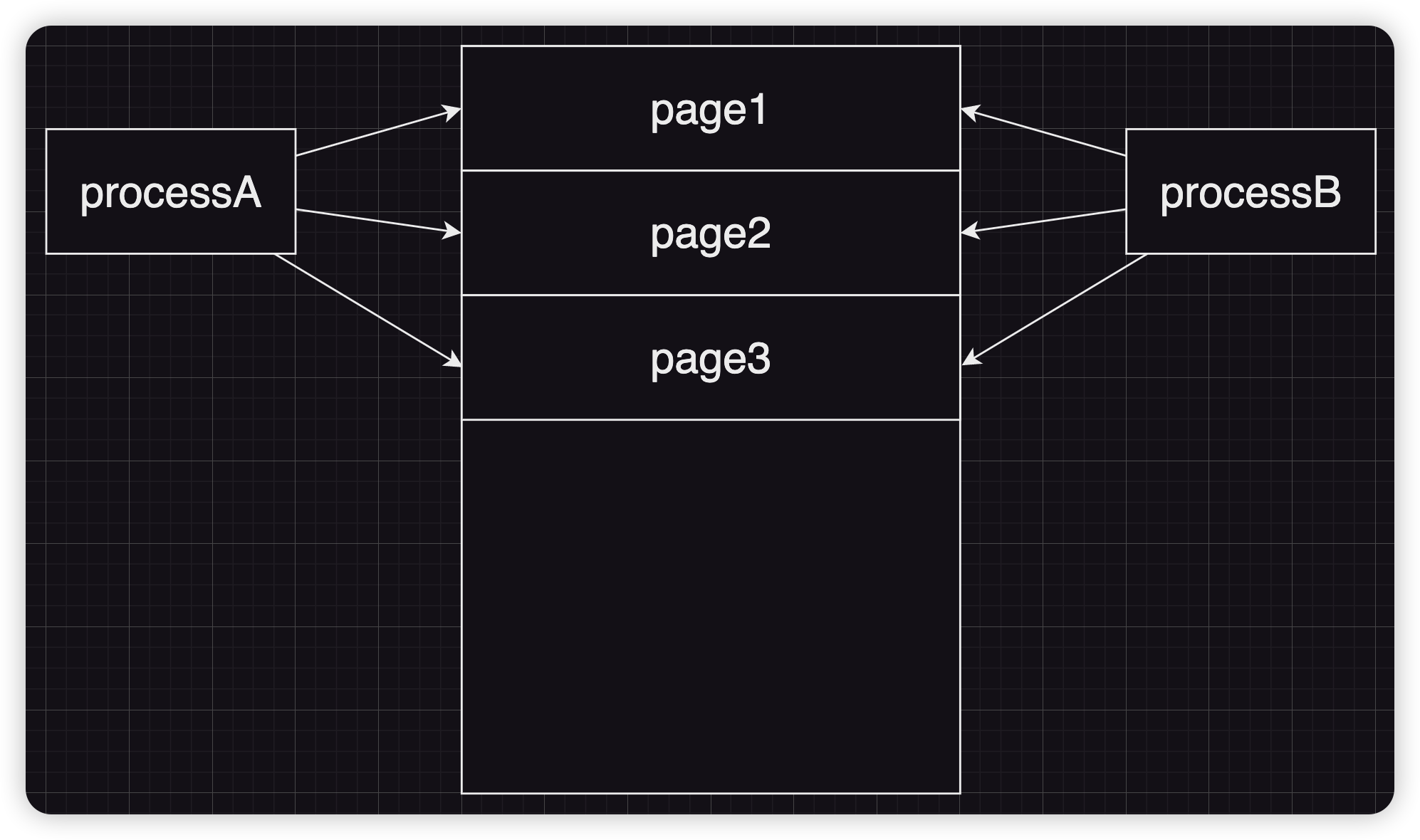
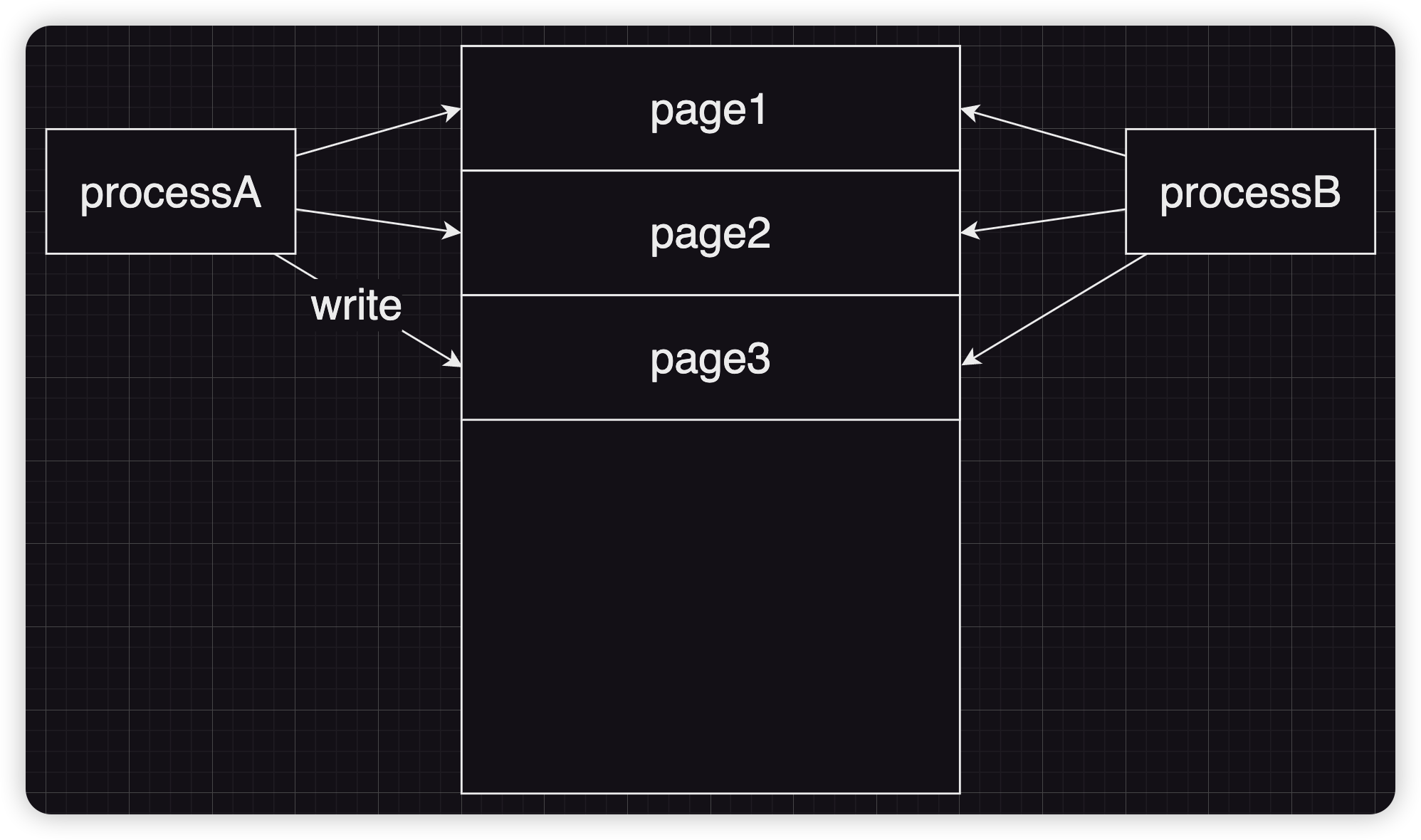
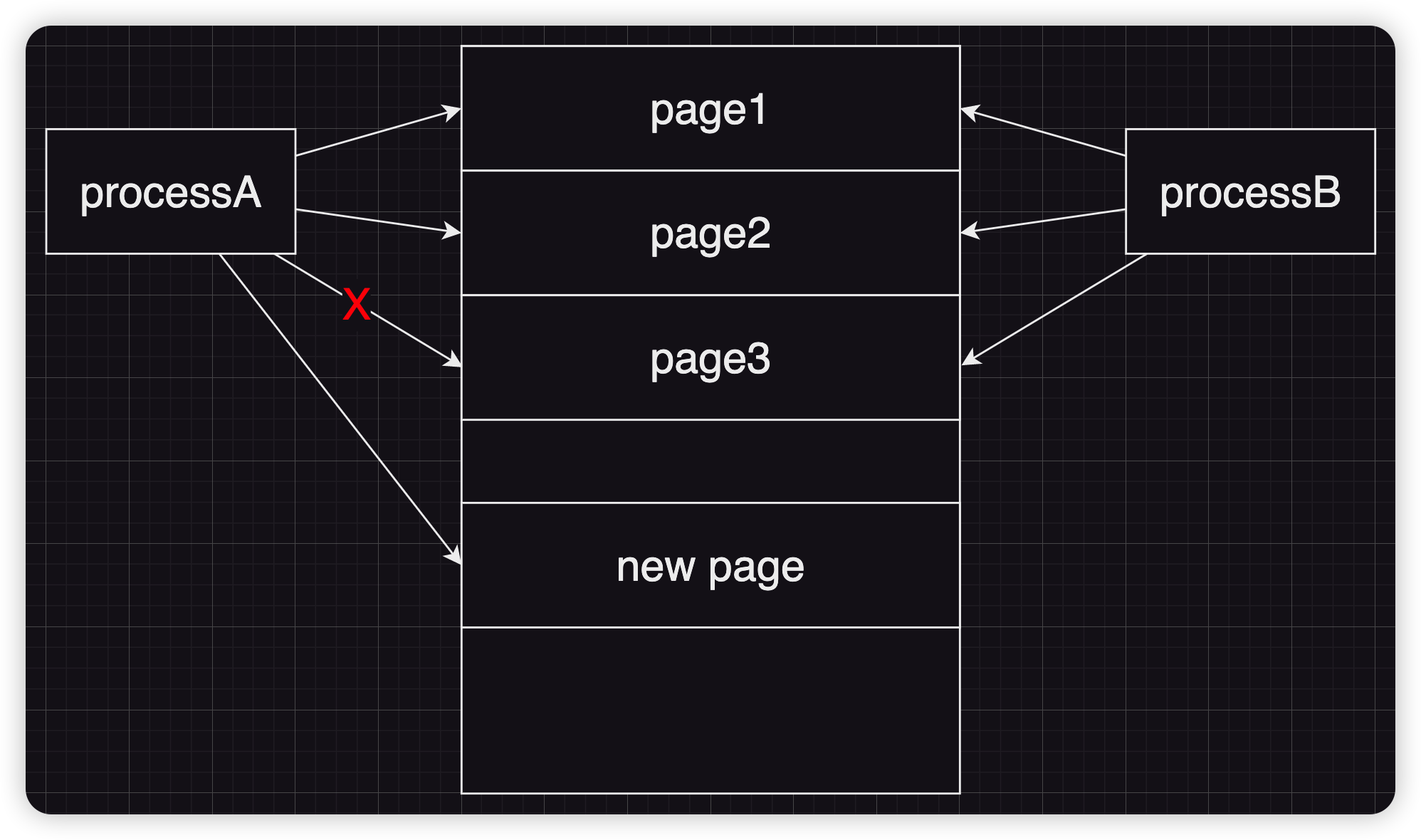
COW 即 copy on write:目的是为了降低系统的开销,在一个进程通过fork()创建一个子进程时,并不会直接将父进程的所有地址空间的所有内容复制再分配给子进程。而实际的机制为父进程与子进程共享所有的页框,而不是直接给子进程分配新的页框,只有当其中任意一方尝试向页框写入内容时内核才会为其分配页框,并将原本内框的内容复制过去。
硬性缺页异常则意味着使用的页并没有被载入到内存中,此时操作系统则需要讲一个合适并且空闲的物理页载入进内存中,随后向该页中写入内容,并在MMU中注册。硬性缺页异常的开销极大,因此部分操作系统也会采取延迟页载入的策略——只有到万不得已时才会分配新的物理页,这也是 Linux 内核的做法。若是频繁地发生硬性缺页异常则会引发系统颠簸,因资源耗尽而无法正常完成工作。
/* * Detect and handle instructions that would cause a page fault for * both a tracked kernel page and a userspace page. */ if (kmemcheck_active(regs)) kmemcheck_hide(regs); prefetchw(&mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address))) return;
/* * We fault-in kernel-space virtual memory on-demand. The * 'reference' page table is init_mm.pgd. * * NOTE! We MUST NOT take any locks for this case. We may * be in an interrupt or a critical region, and should * only copy the information from the master page table, * nothing more. * * This verifies that the fault happens in kernel space * (error_code & 4) == 0, and that the fault was not a * protection error (error_code & 9) == 0. */ if (unlikely(fault_in_kernel_space(address))) { if (!(error_code & (PF_RSVD | PF_USER | PF_PROT))) { if (vmalloc_fault(address) >= 0) return;
if (kmemcheck_fault(regs, address, error_code)) return; }
/* Can handle a stale RO->RW TLB: */ if (spurious_fault(error_code, address)) return;
/* kprobes don't want to hook the spurious faults: */ if (kprobes_fault(regs)) return; /* * Don't take the mm semaphore here. If we fixup a prefetch * fault we could otherwise deadlock: */ bad_area_nosemaphore(regs, error_code, address);
return; }
/* kprobes don't want to hook the spurious faults: */ if (unlikely(kprobes_fault(regs))) return;
if (unlikely(error_code & PF_RSVD)) pgtable_bad(regs, error_code, address);
if (unlikely(smap_violation(error_code, regs))) { bad_area_nosemaphore(regs, error_code, address); return; }
/* * If we're in an interrupt, have no user context or are running * in a region with pagefaults disabled then we must not take the fault */ if (unlikely(faulthandler_disabled() || !mm)) { bad_area_nosemaphore(regs, error_code, address); return; }
/* * It's safe to allow irq's after cr2 has been saved and the * vmalloc fault has been handled. * * User-mode registers count as a user access even for any * potential system fault or CPU buglet: */ if (user_mode(regs)) { local_irq_enable(); error_code |= PF_USER; flags |= FAULT_FLAG_USER; } else { if (regs->flags & X86_EFLAGS_IF) local_irq_enable(); }
if (error_code & PF_WRITE) flags |= FAULT_FLAG_WRITE;
/* * When running in the kernel we expect faults to occur only to * addresses in user space. All other faults represent errors in * the kernel and should generate an OOPS. Unfortunately, in the * case of an erroneous fault occurring in a code path which already * holds mmap_sem we will deadlock attempting to validate the fault * against the address space. Luckily the kernel only validly * references user space from well defined areas of code, which are * listed in the exceptions table. * * As the vast majority of faults will be valid we will only perform * the source reference check when there is a possibility of a * deadlock. Attempt to lock the address space, if we cannot we then * validate the source. If this is invalid we can skip the address * space check, thus avoiding the deadlock: */ if (unlikely(!down_read_trylock(&mm->mmap_sem))) { if ((error_code & PF_USER) == 0 && !search_exception_tables(regs->ip)) { bad_area_nosemaphore(regs, error_code, address); return; } retry: down_read(&mm->mmap_sem); } else { /* * The above down_read_trylock() might have succeeded in * which case we'll have missed the might_sleep() from * down_read(): */ might_sleep(); }
vma = find_vma(mm, address); if (unlikely(!vma)) { bad_area(regs, error_code, address); return; } if (likely(vma->vm_start <= address)) goto good_area; if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) { bad_area(regs, error_code, address); return; } if (error_code & PF_USER) { /* * Accessing the stack below %sp is always a bug. * The large cushion allows instructions like enter * and pusha to work. ("enter $65535, $31" pushes * 32 pointers and then decrements %sp by 65535.) */ if (unlikely(address + 65536 + 32 * sizeof(unsignedlong) < regs->sp)) { bad_area(regs, error_code, address); return; } } if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; }
/* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ good_area: if (unlikely(access_error(error_code, vma))) { bad_area_access_error(regs, error_code, address); return; }
/* * If for any reason at all we couldn't handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault. Since we never set FAULT_FLAG_RETRY_NOWAIT, if * we get VM_FAULT_RETRY back, the mmap_sem has been unlocked. */ fault = handle_mm_fault(mm, vma, address, flags); major |= fault & VM_FAULT_MAJOR;
/* * If we need to retry the mmap_sem has already been released, * and if there is a fatal signal pending there is no guarantee * that we made any progress. Handle this case first. */ if (unlikely(fault & VM_FAULT_RETRY)) { /* Retry at most once */ if (flags & FAULT_FLAG_ALLOW_RETRY) { flags &= ~FAULT_FLAG_ALLOW_RETRY; flags |= FAULT_FLAG_TRIED; if (!fatal_signal_pending(tsk)) goto retry; }
/* User mode? Just return to handle the fatal exception */ if (flags & FAULT_FLAG_USER) return;
/* Not returning to user mode? Handle exceptions or die: */ no_context(regs, error_code, address, SIGBUS, BUS_ADRERR); return; }
/* * Major/minor page fault accounting. If any of the events * returned VM_FAULT_MAJOR, we account it as a major fault. */ if (major) { tsk->maj_flt++; perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs, address); } else { tsk->min_flt++; perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs, address); }
if (unlikely(is_vm_hugetlb_page(vma))) return hugetlb_fault(mm, vma, address, flags);
pgd = pgd_offset(mm, address); pud = pud_alloc(mm, pgd, address); if (!pud) return VM_FAULT_OOM; pmd = pmd_alloc(mm, pud, address); if (!pmd) return VM_FAULT_OOM; if (pmd_none(*pmd) && transparent_hugepage_enabled(vma)) { int ret = create_huge_pmd(mm, vma, address, pmd, flags); if (!(ret & VM_FAULT_FALLBACK)) return ret; } else { pmd_t orig_pmd = *pmd; int ret;
barrier(); if (pmd_trans_huge(orig_pmd)) { unsignedint dirty = flags & FAULT_FLAG_WRITE;
/* * If the pmd is splitting, return and retry the * the fault. Alternative: wait until the split * is done, and goto retry. */ if (pmd_trans_splitting(orig_pmd)) return0;
if (pmd_protnone(orig_pmd)) return do_huge_pmd_numa_page(mm, vma, address, orig_pmd, pmd);
/* * Use __pte_alloc instead of pte_alloc_map, because we can't * run pte_offset_map on the pmd, if an huge pmd could * materialize from under us from a different thread. */ if (unlikely(pmd_none(*pmd)) && unlikely(__pte_alloc(mm, vma, pmd, address))) return VM_FAULT_OOM; /* if an huge pmd materialized from under us just retry later */ if (unlikely(pmd_trans_huge(*pmd))) return0; /* * A regular pmd is established and it can't morph into a huge pmd * from under us anymore at this point because we hold the mmap_sem * read mode and khugepaged takes it in write mode. So now it's * safe to run pte_offset_map(). */ pte = pte_offset_map(pmd, address);
/* * some architectures can have larger ptes than wordsize, * e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and CONFIG_32BIT=y, * so READ_ONCE or ACCESS_ONCE cannot guarantee atomic accesses. * The code below just needs a consistent view for the ifs and * we later double check anyway with the ptl lock held. So here * a barrier will do. */ entry = *pte; barrier(); if (!pte_present(entry)) { if (pte_none(entry)) { if (vma_is_anonymous(vma)) return do_anonymous_page(mm, vma, address, pte, pmd, flags); else return do_fault(mm, vma, address, pte, pmd, flags, entry); } return do_swap_page(mm, vma, address, pte, pmd, flags, entry); }
if (pte_protnone(entry)) return do_numa_page(mm, vma, address, entry, pte, pmd);
ptl = pte_lockptr(mm, pmd); spin_lock(ptl); if (unlikely(!pte_same(*pte, entry))) goto unlock; if (flags & FAULT_FLAG_WRITE) { if (!pte_write(entry)) return do_wp_page(mm, vma, address, pte, pmd, ptl, entry); entry = pte_mkdirty(entry); } entry = pte_mkyoung(entry); if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) { update_mmu_cache(vma, address, pte); } else { /* * This is needed only for protection faults but the arch code * is not yet telling us if this is a protection fault or not. * This still avoids useless tlb flushes for .text page faults * with threads. */ if (flags & FAULT_FLAG_WRITE) flush_tlb_fix_spurious_fault(vma, address); } unlock: pte_unmap_unlock(pte, ptl); return0; }
if (unlikely(anon_vma_prepare(vma))) return VM_FAULT_OOM;
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address); if (!new_page) return VM_FAULT_OOM;
if (mem_cgroup_try_charge(new_page, mm, GFP_KERNEL, &memcg)) { page_cache_release(new_page); return VM_FAULT_OOM; }
ret = __do_fault(vma, address, pgoff, flags, new_page, &fault_page); if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY))) goto uncharge_out;
if (fault_page) copy_user_highpage(new_page, fault_page, address, vma); __SetPageUptodate(new_page);
pte = pte_offset_map_lock(mm, pmd, address, &ptl); if (unlikely(!pte_same(*pte, orig_pte))) { pte_unmap_unlock(pte, ptl); if (fault_page) { unlock_page(fault_page); page_cache_release(fault_page); } else { /* * The fault handler has no page to lock, so it holds * i_mmap_lock for read to protect against truncate. */ i_mmap_unlock_read(vma->vm_file->f_mapping); } goto uncharge_out; } do_set_pte(vma, address, new_page, pte, true, true); mem_cgroup_commit_charge(new_page, memcg, false); lru_cache_add_active_or_unevictable(new_page, vma); pte_unmap_unlock(pte, ptl); if (fault_page) { unlock_page(fault_page); page_cache_release(fault_page); } else { /* * The fault handler has no page to lock, so it holds * i_mmap_lock for read to protect against truncate. */ i_mmap_unlock_read(vma->vm_file->f_mapping); } return ret; uncharge_out: mem_cgroup_cancel_charge(new_page, memcg); page_cache_release(new_page); return ret; }
old_page = vm_normal_page(vma, address, orig_pte); if (!old_page) { /* * VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a * VM_PFNMAP VMA. * * We should not cow pages in a shared writeable mapping. * Just mark the pages writable and/or call ops->pfn_mkwrite. */ if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) == (VM_WRITE|VM_SHARED)) return wp_pfn_shared(mm, vma, address, page_table, ptl, orig_pte, pmd);
down_read(&mm->mmap_sem); /* ignore errors, just check how much was successfully transferred */ while (len) { int bytes, ret, offset; void *maddr; structpage *page =NULL;
ret = get_user_pages(tsk, mm, addr, 1, write, 1, &page, &vma); if (ret <= 0) { #ifndef CONFIG_HAVE_IOREMAP_PROT break; #else /* * Check if this is a VM_IO | VM_PFNMAP VMA, which * we can access using slightly different code. */ vma = find_vma(mm, addr); if (!vma || vma->vm_start > addr) break; if (vma->vm_ops && vma->vm_ops->access) ret = vma->vm_ops->access(vma, addr, buf, len, write); if (ret <= 0) break; bytes = ret; #endif } else { bytes = len; offset = addr & (PAGE_SIZE-1); if (bytes > PAGE_SIZE-offset) bytes = PAGE_SIZE-offset;
long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm, unsignedlong start, unsignedlong nr_pages, unsignedint gup_flags, struct page **pages, struct vm_area_struct **vmas, int *nonblocking) { long i = 0; unsignedint page_mask; structvm_area_struct *vma =NULL;
if (!nr_pages) return0;
VM_BUG_ON(!!pages != !!(gup_flags & FOLL_GET));
/* * If FOLL_FORCE is set then do not force a full fault as the hinting * fault information is unrelated to the reference behaviour of a task * using the address space */ if (!(gup_flags & FOLL_FORCE)) gup_flags |= FOLL_NUMA;
do { structpage *page; unsignedint foll_flags = gup_flags; unsignedint page_increm;
/* first iteration or cross vma bound */ if (!vma || start >= vma->vm_end) { vma = find_extend_vma(mm, start); if (!vma && in_gate_area(mm, start)) { int ret; ret = get_gate_page(mm, start & PAGE_MASK, gup_flags, &vma, pages ? &pages[i] : NULL); if (ret) return i ? : ret; page_mask = 0; goto next_page; }
if (!vma || check_vma_flags(vma, gup_flags)) return i ? : -EFAULT; if (is_vm_hugetlb_page(vma)) { i = follow_hugetlb_page(mm, vma, pages, vmas, &start, &nr_pages, i, gup_flags); continue; } } retry: /* * If we have a pending SIGKILL, don't keep faulting pages and * potentially allocating memory. */ if (unlikely(fatal_signal_pending(current))) return i ? i : -ERESTARTSYS; cond_resched(); page = follow_page_mask(vma, start, foll_flags, &page_mask); if (!page) { int ret; ret = faultin_page(tsk, vma, start, &foll_flags, nonblocking); switch (ret) { case0: goto retry; case -EFAULT: case -ENOMEM: case -EHWPOISON: return i ? i : ret; case -EBUSY: return i; case -ENOENT: goto next_page; } BUG(); } elseif (PTR_ERR(page) == -EEXIST) { /* * Proper page table entry exists, but no corresponding * struct page. */ goto next_page; } elseif (IS_ERR(page)) { return i ? i : PTR_ERR(page); } if (pages) { pages[i] = page; flush_anon_page(vma, page, start); flush_dcache_page(page); page_mask = 0; } next_page: if (vmas) { vmas[i] = vma; page_mask = 0; } page_increm = 1 + (~(start >> PAGE_SHIFT) & page_mask); if (page_increm > nr_pages) page_increm = nr_pages; i += page_increm; start += page_increm * PAGE_SIZE; nr_pages -= page_increm; } while (nr_pages); return i; } EXPORT_SYMBOL(__get_user_pages);
/* mlock all present pages, but do not fault in new pages */ if ((*flags & (FOLL_POPULATE | FOLL_MLOCK)) == FOLL_MLOCK) return -ENOENT; /* For mm_populate(), just skip the stack guard page. */ if ((*flags & FOLL_POPULATE) && (stack_guard_page_start(vma, address) || stack_guard_page_end(vma, address + PAGE_SIZE))) return -ENOENT; if (*flags & FOLL_WRITE) fault_flags |= FAULT_FLAG_WRITE; if (nonblocking) fault_flags |= FAULT_FLAG_ALLOW_RETRY; if (*flags & FOLL_NOWAIT) fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_RETRY_NOWAIT; if (*flags & FOLL_TRIED) { VM_WARN_ON_ONCE(fault_flags & FAULT_FLAG_ALLOW_RETRY); fault_flags |= FAULT_FLAG_TRIED; }
ret = handle_mm_fault(mm, vma, address, fault_flags); if (ret & VM_FAULT_ERROR) { if (ret & VM_FAULT_OOM) return -ENOMEM; if (ret & (VM_FAULT_HWPOISON | VM_FAULT_HWPOISON_LARGE)) return *flags & FOLL_HWPOISON ? -EHWPOISON : -EFAULT; if (ret & (VM_FAULT_SIGBUS | VM_FAULT_SIGSEGV)) return -EFAULT; BUG(); }
if (tsk) { if (ret & VM_FAULT_MAJOR) tsk->maj_flt++; else tsk->min_flt++; }
if (ret & VM_FAULT_RETRY) { if (nonblocking) *nonblocking = 0; return -EBUSY; }
/* * The VM_FAULT_WRITE bit tells us that do_wp_page has broken COW when * necessary, even if maybe_mkwrite decided not to set pte_write. We * can thus safely do subsequent page lookups as if they were reads. * But only do so when looping for pte_write is futile: in some cases * userspace may also be wanting to write to the gotten user page, * which a read fault here might prevent (a readonly page might get * reCOWed by userspace write). */ if ((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE)) *flags &= ~FOLL_WRITE; return0; }
在分析之前,首先看一下madvise系统调用,madvise一共有三个参数,第一个参数为地址,第二参数为范围,第三个参数为行为。而这个函数的作用就是建议内核,在从 addr 指定的地址开始,长度等于 len 参数值的范围内,该区域的用户虚拟内存应遵循特定的使用模式。内核使用这些信息优化与指定范围关联的资源的处理和维护过程。而其中存在一个MADV_DONTNEED参数我所理解的就是去除对应的表项,并且被内核标记,在被需要时可以被重新使用。
/* * Let's call ->map_pages() first and use ->fault() as fallback * if page by the offset is not ready to be mapped (cold cache or * something). */ if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) { pte = pte_offset_map_lock(mm, pmd, address, &ptl); do_fault_around(vma, address, pte, pgoff, flags); if (!pte_same(*pte, orig_pte)) goto unlock_out; pte_unmap_unlock(pte, ptl); }
ret = __do_fault(vma, address, pgoff, flags, NULL, &fault_page); if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY))) return ret;